Introducción
Para quién está dirigido este curso?
Este curso corresponde con el material que me hubiera gustado encontrarme cuando empecé mi andadura con la Inteligencia Artificial allá en 2017.
Para la gente que venimos de grados de ingeniería (en mi caso estudié Ingeniería Informática), según la formación que hayas tenido, explorar la literatura de Machine Learning puede resultar abrumador. Álgebra, Cálculo, Estadística... son asignaturas muy importantes para este campo, pero se dan en los primeros cursos y tienden a olvidarse llegados a los últimos. En consecuencia, entender conceptos como la transformación de densidades, la optimización del ELBO o el score matching puede sentirse como una barrera complicada de superar.
Entonces, respondiendo a la pregunta: este curso va dirigido a cualquier persona (que tenga un mínimo background técnico) que se sienta identificada con esta situación. El objetivo es poder acompañarte a aprender sobre modelos generativos de forma que entiendas los conceptos subyacentes más importantes, pero que a su vez puedas utilizarlos desde un punto de vista práctico y para casos de uso reales.
Por el contrario, si estás buscando material que profundice en conocimientos de estadística, cálculo, probabilidad, etc, este no es el sitio. En Internet puedes encontrar muchísimo contenido de alta calidad mejor que estos apuntes.
PD: A pesar de la estética y de que intente dejar las explicaciones lo más claras posibles, entender y consolidar el conocimiento es algo que lleva tiempo.
"Learning is not supposed to be fun. It doesn't have to be actively not fun either, but the primary feeling should be that of effort." — Andrej Karpathy
IA Generativa
Como puedes ver en el gráfico, dentro del landscape de Inteligencia Artificial, la IA Generativa se refiere a aquella serie de métodos y técnicas para generar nuevas muestras de datos.
Desde el punto de vista probabilístico, ajustamos un modelo a la distribución de datos con la que se entrena , para, una vez modelado, poder samplear a partir de él y así generar nuevas muestras.
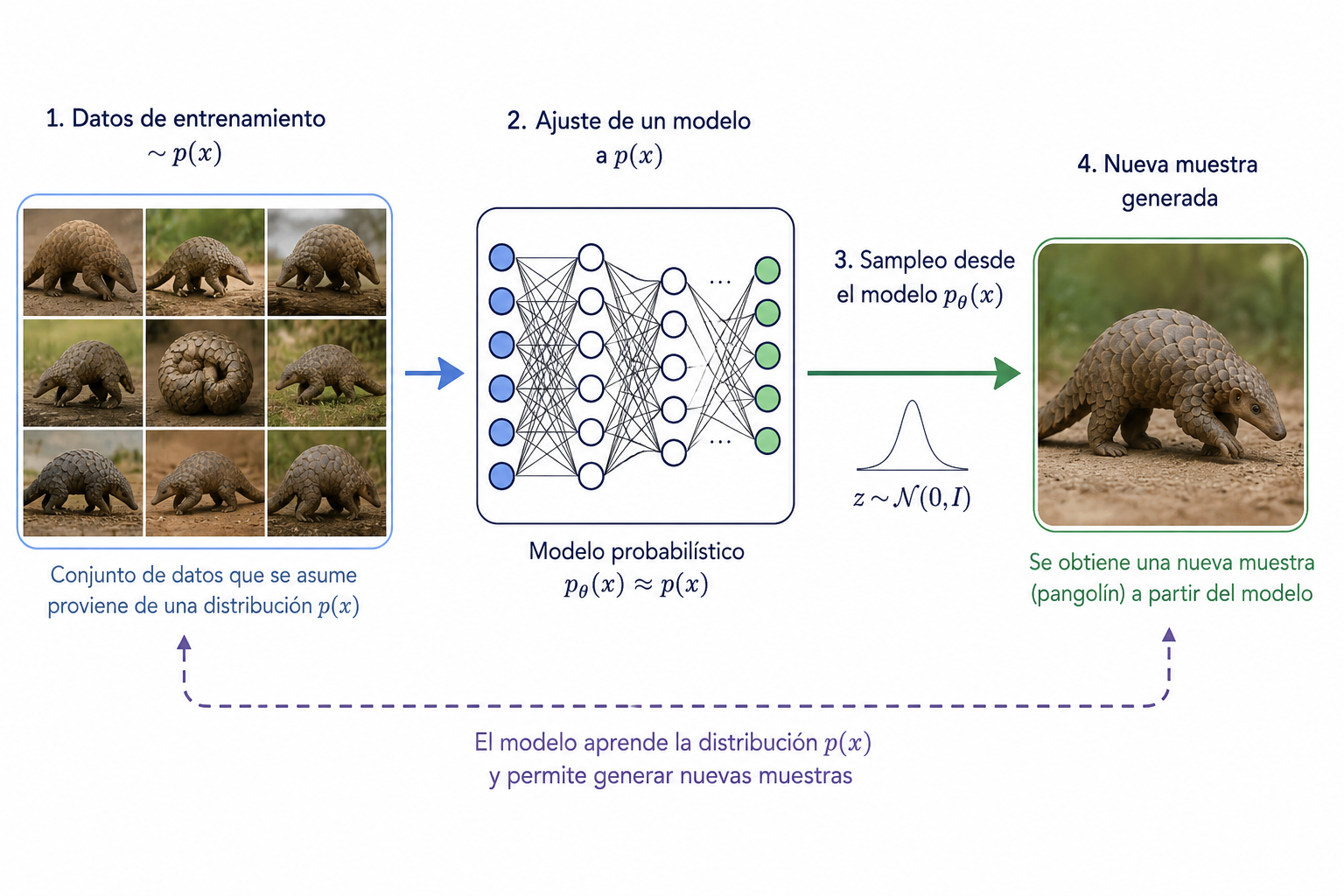
Esto, por supuesto, es aplicable a diversos dominios. Aquí te dejo algunos ejemplos que seguramente ya conoces.
Generación de imágenes
Dalle, Stable Diffusion, Adobe Firefly, Midjourney, Flux…
Actualidad: Nano Banana (Google), Image 2 (OpenAI)

Generación de texto / código
ChatGPT, Claude, Gemini, Grok, Mixtral…
Generación de audio
Wavenet, Vall-e, Stable Audio, Udio…
Actualidad: Suno, Eleven Labs
Modelos generativos condicionales
Generalmente, utilizamos modelos generativos condicionales de la forma para poder controlar lo que generamos. Algunos ejemplos:
- = texto, = imagen: modelo text-to-image (ejemplo: Nano Banana).
- = imagen, = texto: modelo image-to-text (ejemplo: pásale una imagen a ChatGPT y pídele que te la describa).
- = imagen, = imagen: modelo image-to-image (ejemplo: edición de imágenes en Adobe Firefly).
- = audio, = texto: modelo speech-to-text (ejemplo: Whisper, o cualquier dictado por voz).
- = texto, = audio: modelo text-to-speech (ejemplo: ElevenLabs TTS).
- = secuencia de palabras en inglés, = secuencia de palabras en español: modelo sequence-to-sequence (ejemplo). Aquí también entrarían modelos de generación de texto o de elaboración de resúmenes.
Otras aplicaciones
Lo bueno de modelar una distribución es que no solo te permite generar datos, si no que se pueden hacer muchas otras cosas más. Te dejo aquí algunos ejemplos.
Estimación de densidad
La aplicación más directa. Consiste en evaluar la probabilidad de una muestra de datos observada, es decir, calcular . Esto es útil para problemas como la compresión de datos, detección de anomalías, clasificadores generativos, comparación de modelos, etc.
El enfoque más simplista consiste en utilizar la kernel density estimation o KDE (más sobre KDE). Sin embargo, KDE enfrenta graves limitaciones en espacios de alta dimensión debido a la llamada maldición de la dimensionalidad, donde la densidad de los datos se vuelve extremadamente dispersa.
Las redes generativas modernas superan esta barrera al aprender representaciones latentes compactas y complejas, permitiendo estimar o modelar la densidad de manera mucho más eficiente y escalable en datos de alta dimensionalidad (como imágenes, audio o texto).
Imputación de datos
Consiste en "rellenar" los valores que faltan en un vector o matriz de datos. Por ejemplo, una forma sencilla de rellenar datos perdidos en datos tabulares es utilizar el valor medio de cada columna (imputación del valor medio).
Se puede generalizar esto ajustando un modelo generativo a los datos observados, , y calculando a continuación muestras de . Esto se denomina imputación múltiple.
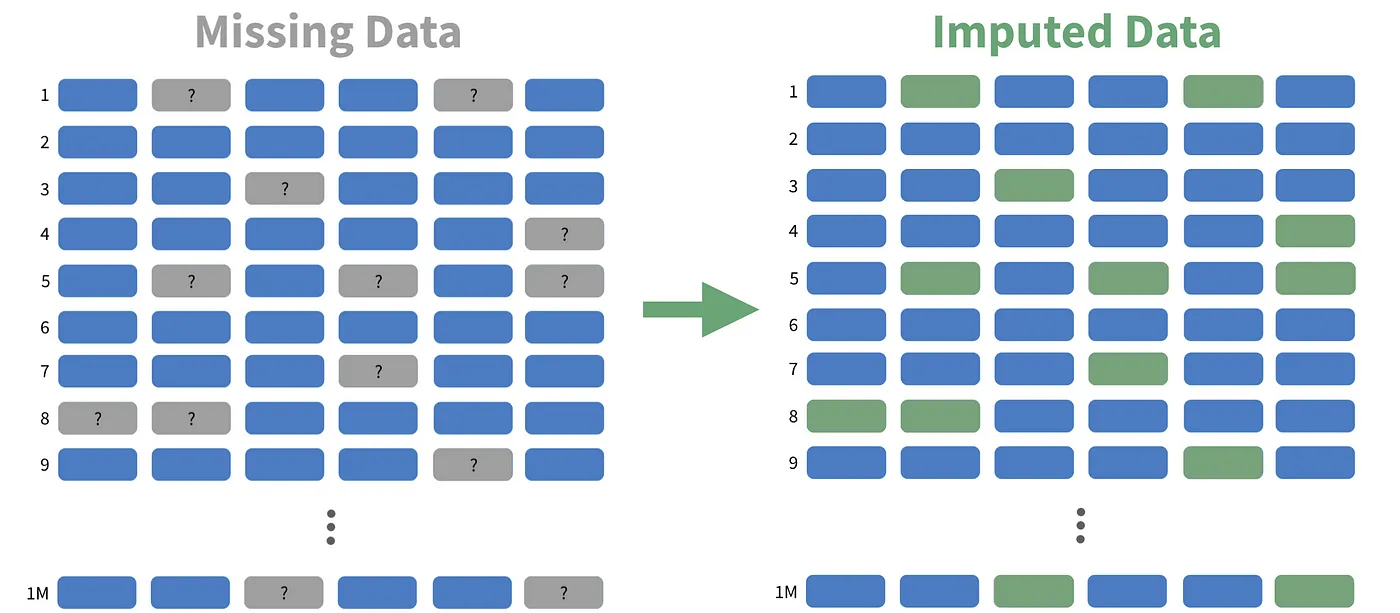
Un modelo generativo puede utilizarse para rellenar tipos de datos más complejos, como píxeles enmascarados en una imagen.
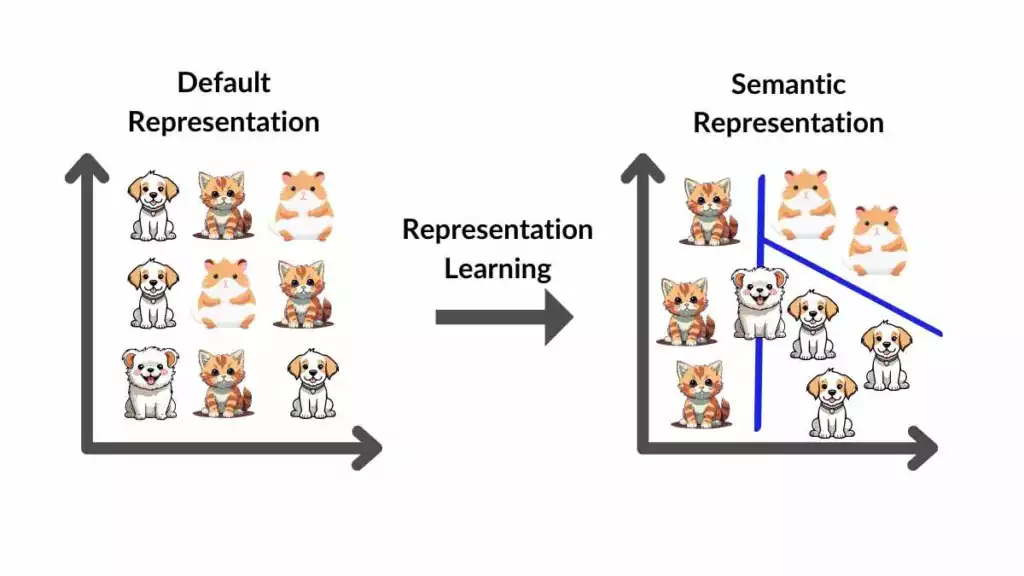
Representation learning
Algunos tipos de modelos generativos tienen variables latentes , que se entienden como las causas que generaron los datos observados . Se pueden explotar estas variables latentes para reducir la dimensionalidad de los datos y descubrir patrones / representaciones útiles.
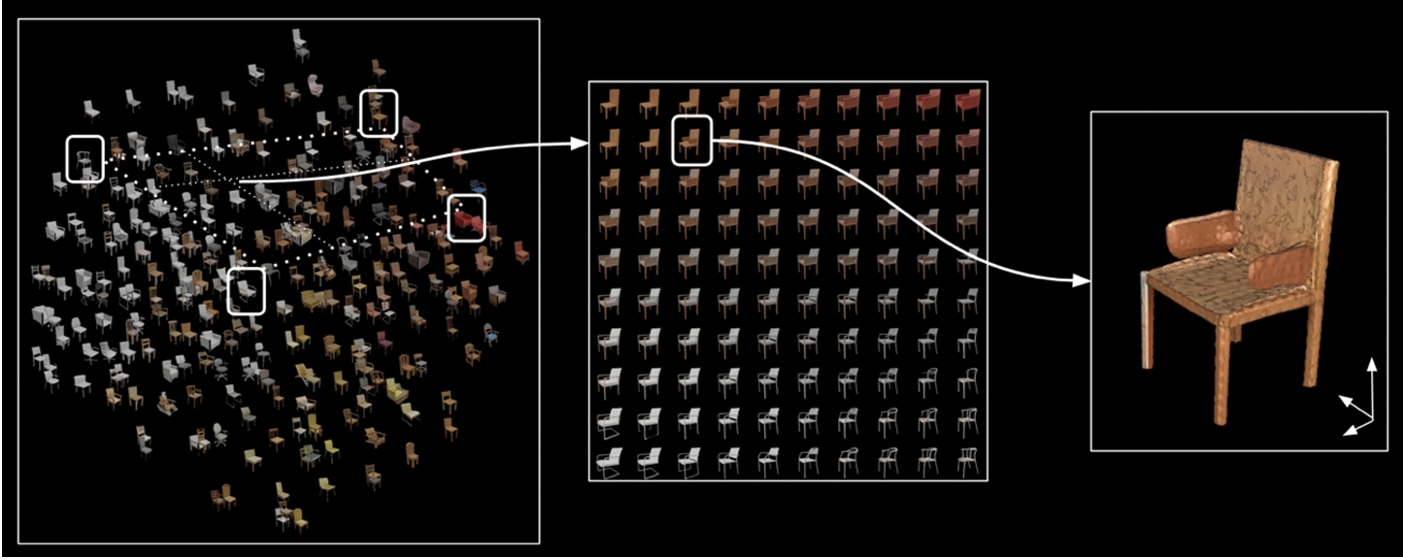
Interpolación en el espacio latente
Lo veremos más adelante pero el espacio latente se refiere al espacio al que los modelos comprimen los datos.
Una de las capacidades más interesantes de ciertos modelos de variables latentes es la posibilidad de generar muestras que tengan ciertas propiedades deseadas interpolando entre puntos de datos existentes en el espacio latente.
En el siguiente ejemplo reducimos la dimensionalidad del espacio latente a dos dimensiones. Elegimos 4 muestras del espacio latente e interpolamos para obtener unas coordenadas 2D. Sampleando a partir de esas coordenadas se obtiene una representación que es una combinación de las 4 muestras seleccionadas.
Compresión de datos
Los modelos que pueden asignar una alta probabilidad a datos que aparecen con frecuencia y una baja probabilidad a los poco frecuentes se pueden utilizar para compresión de datos, ya que se pueden asignar códigos más cortos a los elementos más comunes. De hecho, la longitud de codificación óptima para un vector procedente de una fuente estocástica es , como demostró Shannon. La compresión es un tema aparte muy bonito que se superpone directamente con la Teoría de la Información. Veremos algo de esto en el capítulo de Autoencoders Variacionales.
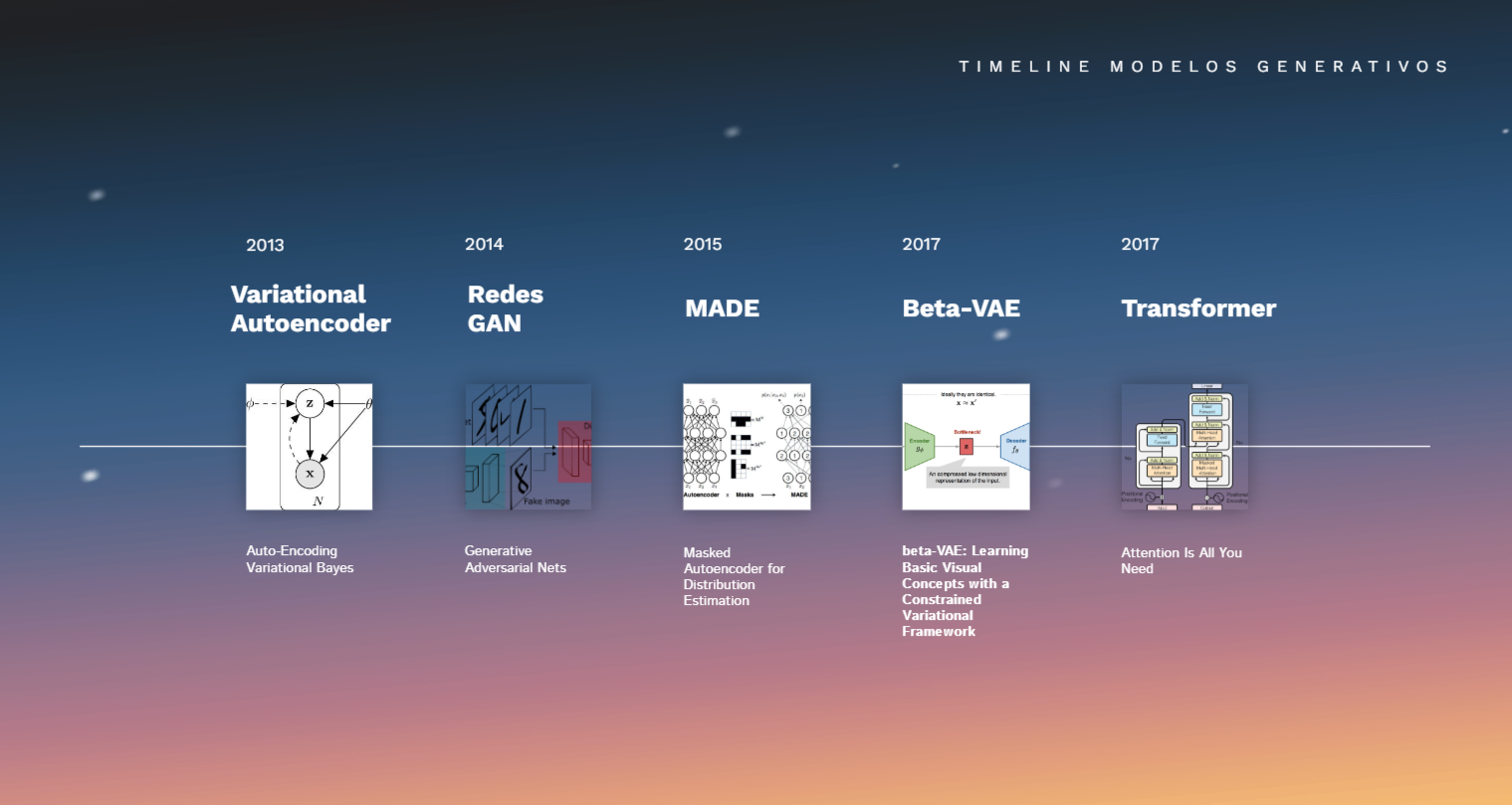
Timeline
Te dejo aquí un timeline resumen de los trabajos más relevantes, en cuanto a IA generativa se refiere, para que entiendas de dónde venimos y hacia dónde estamos yendo.