VAE
Antes de meternos de lleno con los VAEs vamos a hacer un pequeño repaso sobre autoencoders.
Autoencoders
Los autoencoders son una familia de redes neuronales que tiene como objetivo aprender una representación simplificada de los datos de entrada.
Su funcionamiento se basa en comprimir y reconstruir datos. Generalmente, constan de dos redes:
- Un Encoder que comprime los datos de entrada a un espacio de menores dimensiones, conocido como espacio latente, .
- Un Decoder que a partir del espacio latente reconstruye los datos, .
Los parámetros de cada red se optimizan a la vez para que las reconstrucciones sean lo más parecidas a los datos originales, .
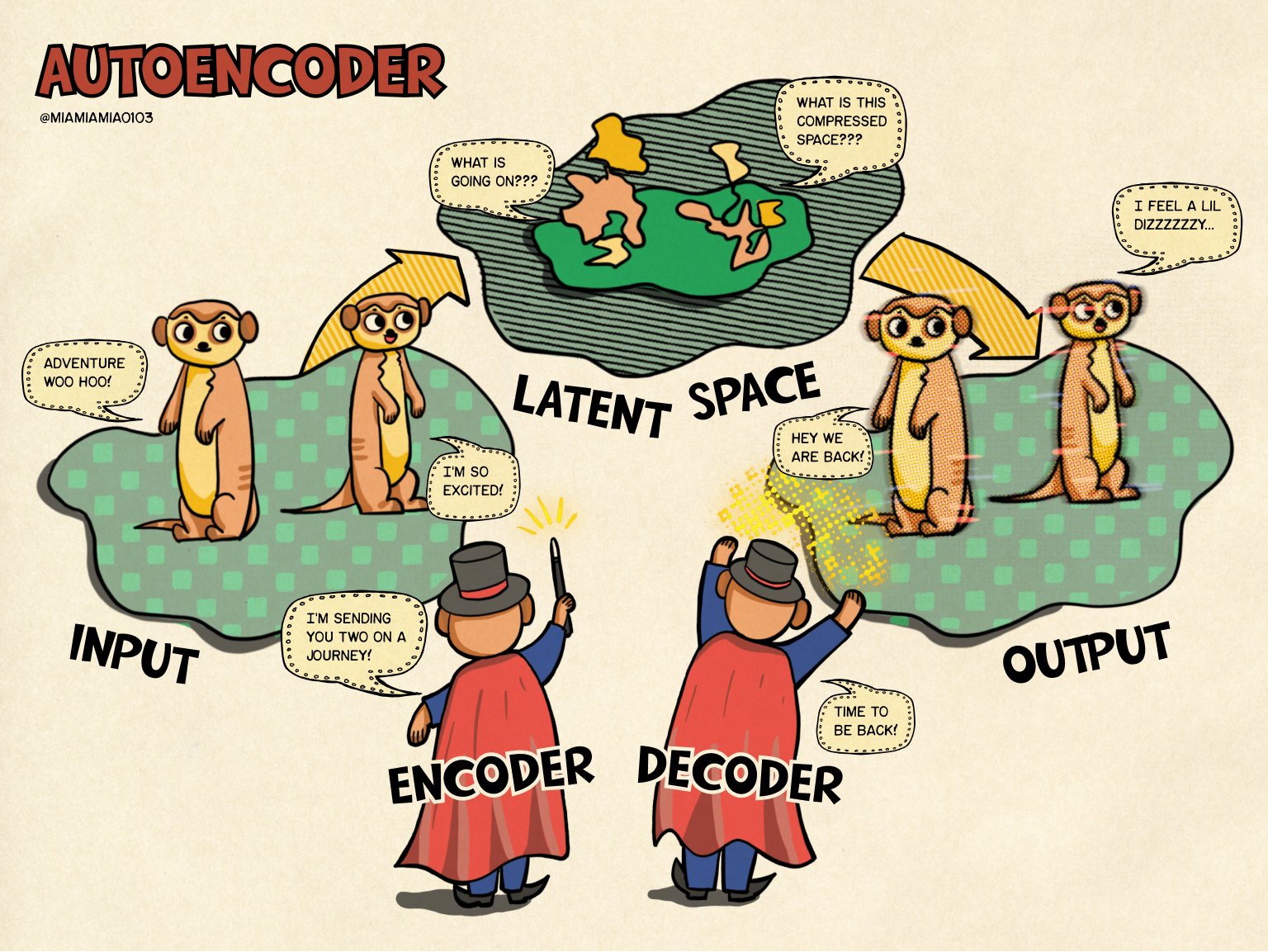
La idea se originó en la década de los 80 y posteriormente fue promovida por Geoffrey Hinton y compañía[hinton2006reducing] en 2006. Es una idea muy intrínseca a los modelos de IA actuales y tiene una aplicación directa a diversas tareas como la detección de anomalías, manifold learning, compresión o generación de datos.
La función de pérdida de un autoencoder convencional mide qué tan bien el modelo puede reconstruir la entrada original una vez comprimidos los datos al espacio latente, por tanto, el objetivo es que la salida sea lo más parecida posible a la entrada . La elección de la función de error depende principalmente de la naturaleza de los datos de entrada.
-
Mean Squared Error (MSE)
Es la función de pérdida más utilizada para datos continuos (por ejemplo, imágenes o series temporales).
El objetivo es minimizar la diferencia al cuadrado entre la entrada original y la salida reconstruida :
-
Binary Cross Entropy
Se utiliza cuando los datos de entrada están normalizados en el rango [0, 1] y se interpretan como probabilidades o cuando los datos son binarios. Es muy común en autoencoders donde la capa de salida tiene una función de activación sigmoide.
Existen muchas variantes de autoencoders como Denoising Autoencoders[vincent2008extracting], Sparse Autoencoders[makhzani2013k] o Contractive Autoencoders[rifai2011contractive]. De aquí en adelante nos centraremos en los Variational AutoEncoders (VAE)[kingma2013auto] por sus propiedades generativas.
En esta librería tenéis varios modelos de autoencoders programados en Keras 3. Se agradece una estrella 😊.
VAE
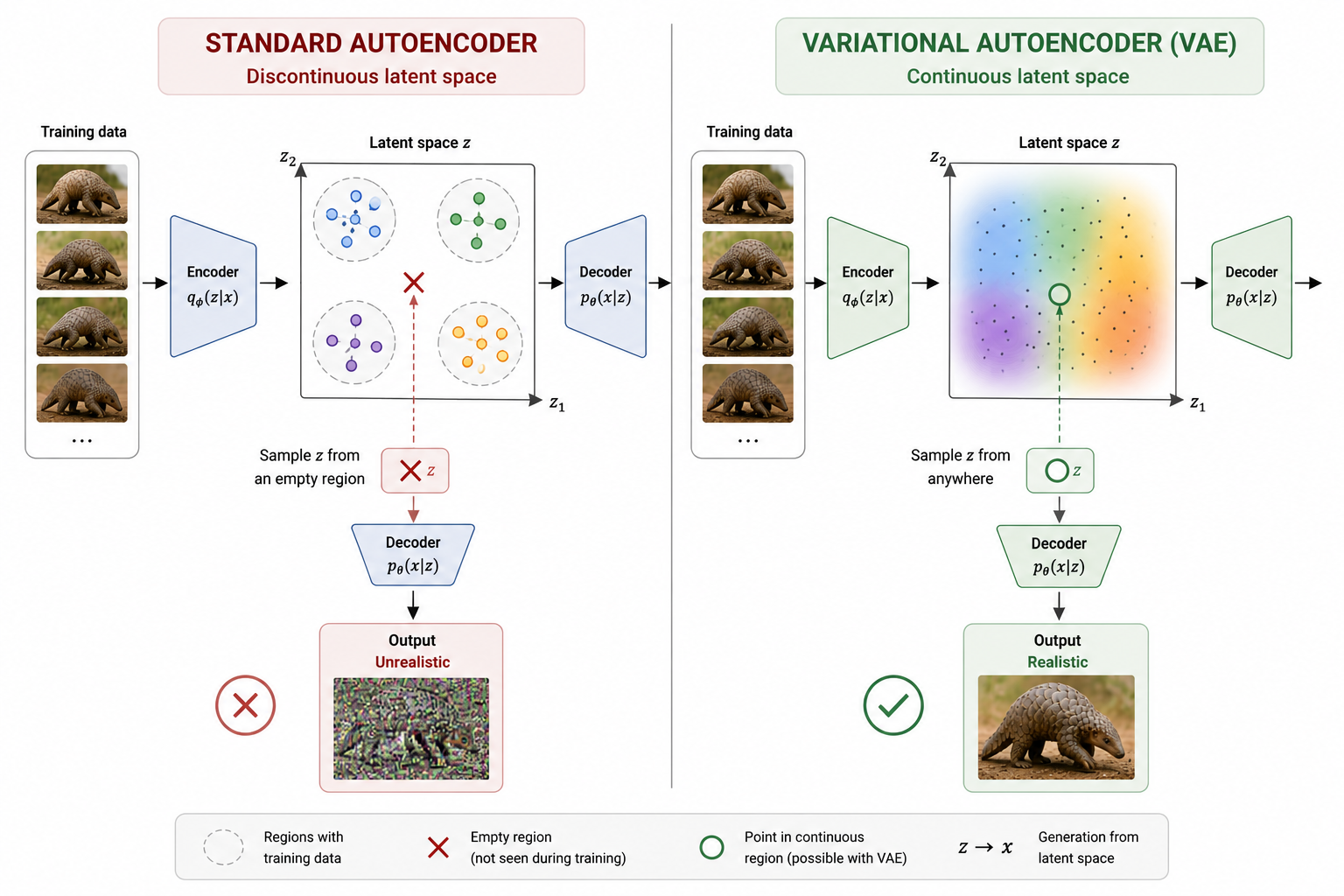
Los autoencoders estándar traducen las entradas a un conjunto de vectores fijo y esto ocasiona que el espacio latente sea discontinuo. Esto se traduce a que si se quisiera elegir un punto del espacio latente donde no existe representación alguna y samplear con el decoder para generar una nueva muestra, la salida será poco realista, porque el decoder no sabe cómo reconstruir una entrada a partir de una región del espacio latente vacía. Con 'vacía' me refiero a que durante el entrenamiento el modelo nunca procesó datos que se codificaran en ese punto del espacio latente.
La novedad que introducen los VAE es que en lugar de mapear los datos a vectores fijos se mapean a una distribución.
Esto tiene la ventaja de que el espacio latente es continuo y, por tanto, se puede elegir un punto que no pertenezca a la proyección de ningún dato de entrenamiento, pasarlo por el decoder y obtener una nueva muestra coherente. Es decir, generar datos en la forma .
Ya tenemos un modelo generativo de variables latentes!
La relación entre los datos de entrada y el vector latente viene dada por:
- Prior:
- Likelihood:
- Posterior:
La distribución de los datos entonces se puede modelar como:
Desafortunadamente, no es fácil calcular , ya que es muy costoso comprobar y sumar todos los valores posibles de (por lo que se suele denominar 'intratable'). Para solucionar este problema, los VAE recurren a la inferencia variacional (de ahí su nombre). Precisamente, la inferencia variacional es uno de los métodos más recurridos de la inferencia bayesiana y se utiliza para aproximar integrales intratables. En otras palabras, es una técnica utilizada para aproximar distribuciones complejas.
La distribución compleja que se quiere aproximar es (posterior). Para aproximarla mediante inferencia variacional, la idea es presuponer una familia de distribuciones simples y plantear la aproximación como un problema de optimización: buscar dentro de la familia de distribuciones la distribución que más se aproxime a la distribución objetivo. denota los parámetros de la familia de distribuciones elegida. Por ejemplo, si asumimos que va a ser una gaussiana, serían la media y la varianza.
De esta manera, se introduce:
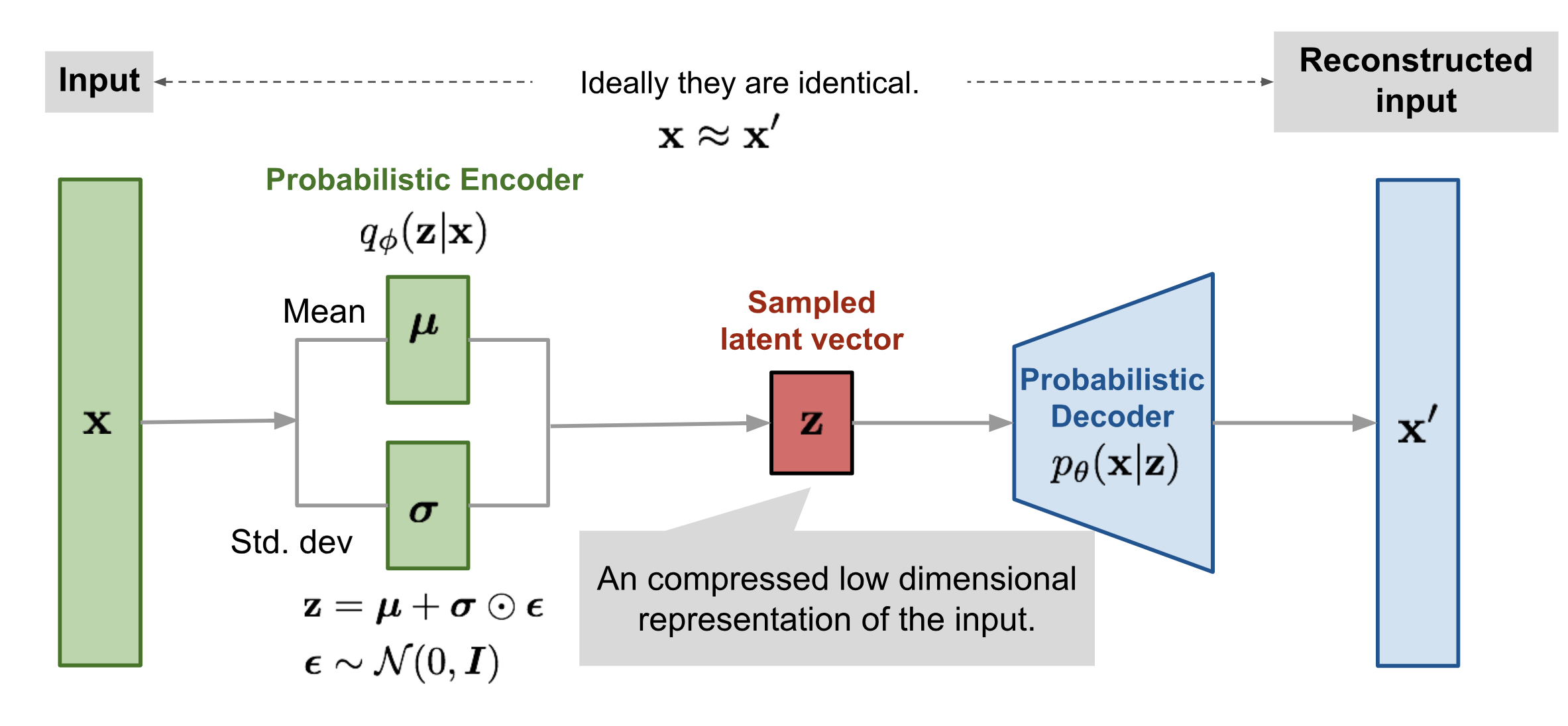
- Una función de aproximación , modelada mediante un encoder para aprender esos parámetros . Es decir, un mecanismo para aproximar la posterior .
- Un decoder que se encarga de modelar la probabilidad condicional . Al aprender , está aprendiendo cómo mapear cualquier punto del espacio latente de vuelta al espacio original de los datos.
Función de error: ELBO
La distribución estimada por el encoder, , debe ser próxima a la real . Para cuantificar la distancia entre estas dos distribuciones se usa la divergencia de Kullback–Leibler, , que se encarga de medir cuánta información se pierde si se usa la distribución para representar .
En este caso, se quiere minimizar con respecto a .
Usando el teorema de Bayes, se puede reescribir como:
- El primer término es el log-likelihood de los datos, que queremos maximizar.
- El segundo término es el log-likelihood esperado de los datos bajo la posterior aproximada (encoder).
- El tercer término es la divergencia KL entre la posterior aproximada y la prior.
Combinando estos términos, se puede definir la función de pérdida de un VAE como:
también conocida como Evidence Lower Bound (ELBO).
- El primer término es la reconstrucción de que tiende a hacer el esquema de codificación-decodificación lo más eficiente posible maximizando el log-likelihood con muestreo de (encoder).
- El segundo término regulariza las variables latentes (representadas por ) minimizando la divergencia KL entre la aproximación variacional (encoder) y la distribución a priori de . Normalmente, la familia de distribuciones simples que elegimos es una normal estándar, por tanto, cuando pasas una entrada por el encoder este te devuelve los valores de y para esa entrada específica.
Aplicaciones
Las aplicaciones de los VAE son innumerables. Algunos ejemplos más allá de la generación de imágenes son su aplicación a modelado de texto y su semántica[yang2017improved], detección de anomalías[lin2020anomaly], estimación de la vida útil de sistemas industriales[costa2022variational], detección de arritmias[costa2021semi] o diseño molecular[de2023population].
Posterior collapse
Los VAE son conocidos por ser susceptibles al posterior collapse. Esto es un problema que se refiere a la situación en la que la posterior aproximada por el encoder colapsa con la prior. Esto signfica que la KL el segundo término de la ELBO se vuelve dominante. Esto causa que el término de reconstrucción tenga muy poco peso y que, por tanto, el decoder tienda a reconstruir los datos no a partir de si no a partir de . Es decir, no tiene en cuenta los datos!!
En consecuencia, el modelo decide que la mejor forma de minimizar el error es haciendo que todas las entradas colapsen en un solo punto en el espacio latente es la representación más fiel a una normal estándar , pero nosotros queremos .
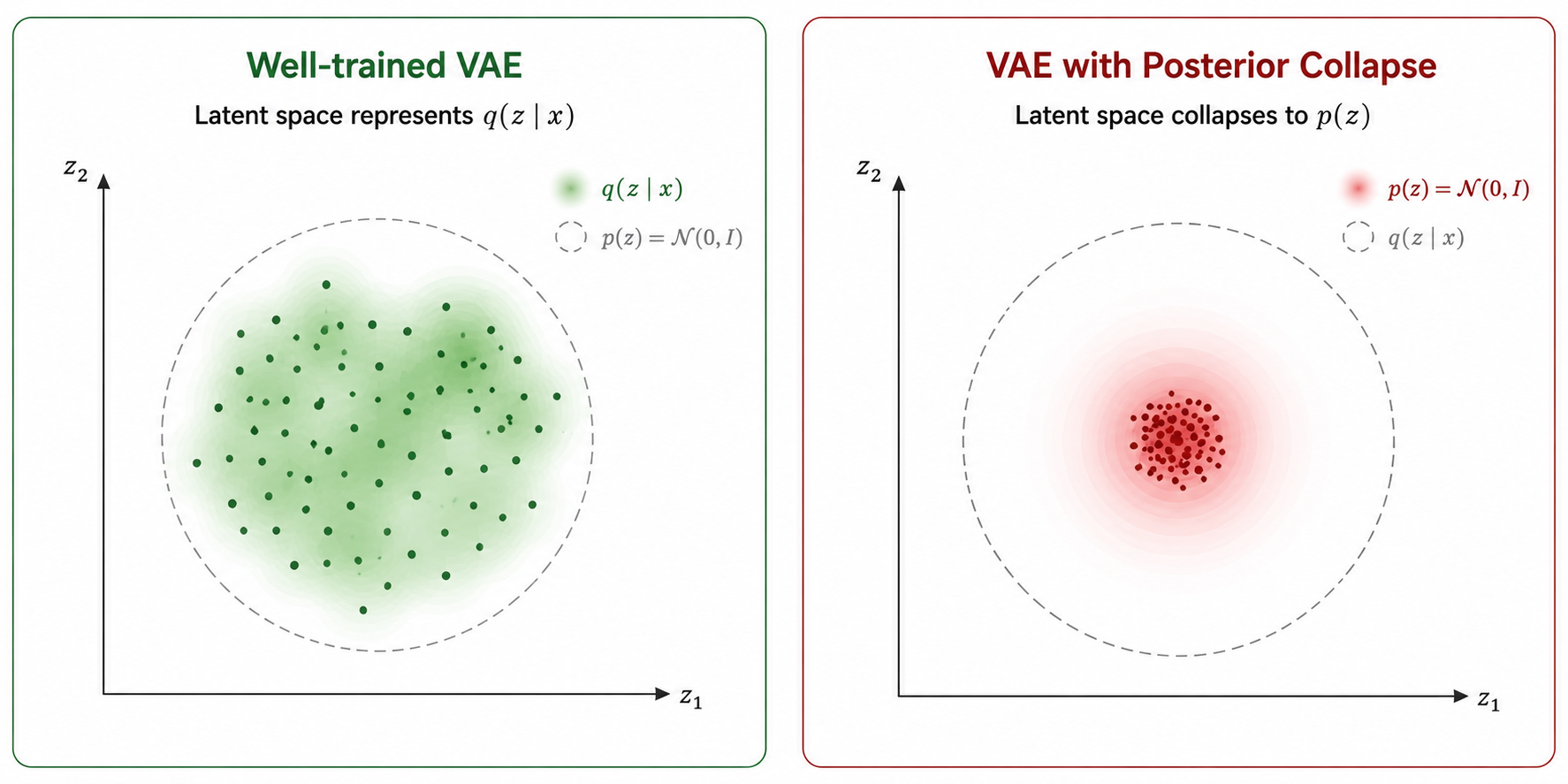
En este caso, las reconstrucciones/generaciones del decoder son incoherentes.
Trucos de entrenamiento
Hay varias aproximaciones para solventar este problema, entre ellas:
- KL Divergence Annealing: incrementa gradualmente el peso del término de divergencia KL en la función de pérdida durante el entrenamiento para permitir que el modelo aprenda primero a reconstruir los datos antes de imponer una regularización fuerte en el espacio latente.
- Free Bits: establece un umbral mínimo para la divergencia KL en cada dimensión de la variable latente, asegurando que cada dimensión contribuya con al menos un "mínimo de información" y evitando que colapsen a valores triviales.
- Minimum Desired Rate: similar a Free Bits, pero aplica una penalización para mantener un mínimo de información en el espacio latente, forzando que la compresión no pierda relevancia.
- Dropout: desconecta aleatoriamente conexiones de la red durante el entrenamiento para evitar que el modelo dependa demasiado de ciertas neuronas, manteniendo así la relevancia de las variables latentes.
- Independent Hidden States: obliga a que las representaciones ocultas del encoder sean independientes entre sí, asegurando que las variables latentes no se vuelvan redundantes o que algunas dimensiones se ignoren.
Variantes del VAE
La literatura de los VAEs es muy extensa y se han propuesto múltiples variantes, así que comentaré solo algunas de ellas.
Otro problema en el entrenamiento de los VAE es que generan imágenes borrosas. Sin embargo, esto no pasa con modelos que optimizan explícitamente la probabilidad de los datos, como los normalizing flows, entonces... ¿por qué aquí sí que ocurre?

Normalmente para cuantificar la calidad de las reconstrucciones se utilizan métricas como RMSE o BCE, como comentamos antes; por lo tanto, la red tiene como objetivo minimizar estas métricas.
Durante el entrenamiento, el modelo puede acertar una reconstrucción en concreto pero fallar en el resto, por lo que el error será alto. Entonces las redes hacen la siguiente trampa: en lugar de acertar reconstrucciones concretas producen para todos los datos generaciones borrosas pero lo suficientemente cercanas a los datos reales, de forma que cuando se hace la media de las reconstrucciones el error obtenido sea bajo.
β-VAE
Se puede resolver este problema modificando el encoder para evitar fusionar entradas distintas en el mismo espacio latente, o el decoder añadiendo información faltante. Sin embargo, una solución aún más sencilla es reducir la penalización sobre el término KL, haciendo que el modelo se acerque más a un autoencoder determinista:
En esto consiste el β-VAE[higgins2017beta] (2017).
Si se fija , la función objetivo es la misma utilizada en los VAE estándar; si se fija a 0, entonces es la misma utilizada por los autoencoders convencionales. Si se usa , se almacenan más bits sobre cada entrada (es decir, se da más importancia a los datos) y, por tanto, se pueden reconstruir las imágenes de forma menos borrosa. Si se utiliza , se obtiene entonces una representación más comprimida.
Con se puede reducir en parte las generaciones borrosas. En contrapartida, una ventaja de utilizar es que fomenta el aprendizaje de una representación latente "desenredada". Intuitivamente, esto significa que cada dimensión latente representa un factor/característica diferente de los datos de entrada. Por ejemplo, un modelo entrenado con fotos de rostros humanos podría captar la suavidad, el color de la piel, el color o la longitud del pelo, la emoción, si se llevan gafas y muchos otros factores relativamente independientes en dimensiones separadas.
En resumen: el diseño de un VAE es casi siempre un juego de equilibrio entre "quiero que se vea bien" y "quiero que el espacio latente tenga sentido".
InfoVAE
Para solucionar el problema de poner demasiado énfasis en el segundo término (la regularización), causando representaciones latentes que no capturan bien la estructura de los datos y muestras generadas que no son diversas, el InfoVAE[zhao2017infovae] (2017) modifica la función de pérdida añadiendo un término de maximización de la información mutua entre las variables latentes y los datos observados . La función de pérdida de InfoVAE se puede escribir como:
Donde el primer término es el error de reconstrucción, el segundo es la divergencia KL entre la distribución posterior aproximada y la prior, y el tercero es la divergencia KL entre la distribución marginal de las variables latentes y la distribución prior.
y son hiperparámetros que controlan la importancia relativa de cada término. De esta manera, al maximizar la información mutua entre y , se asegura que las representaciones latentes contengan más información relevante sobre los datos .
Multimodal VAEs
Los VAE multimodales[wu2018multimodal, shi2019variational] son una extensión del modelo VAE estándar para manejar y aprender representaciones conjuntas de datos provenientes de diferentes modalidades. Estas modalidades pueden incluir texto, imágenes, audio, vídeo, etc. La idea principal es capturar las dependencias y correlaciones entre diferentes tipos de datos, aprendiendo una representación latente compartida que pueda ser utilizada para tareas como la generación o imputación de datos.
Hasta ahora se han propuesto varios enfoques para el aprendizaje multimodal de VAEs; en esta review[sejnova2023benchmarkingmultimodalvariationalautoencoders] se recopilan algunos de los trabajos más influyentes.
Hierarchical VAEs
Un problema de los VAE es que sufren de priors simples. Como hemos visto, asumimos que la prior es una Normal estándar. Una forma de suavizar esto es con jerarquías de variables latentes. Jerarquizando tanto el modelo de inferencia (encoder) como el modelo generativo (decoder) se consiguen mejores probabilidades:
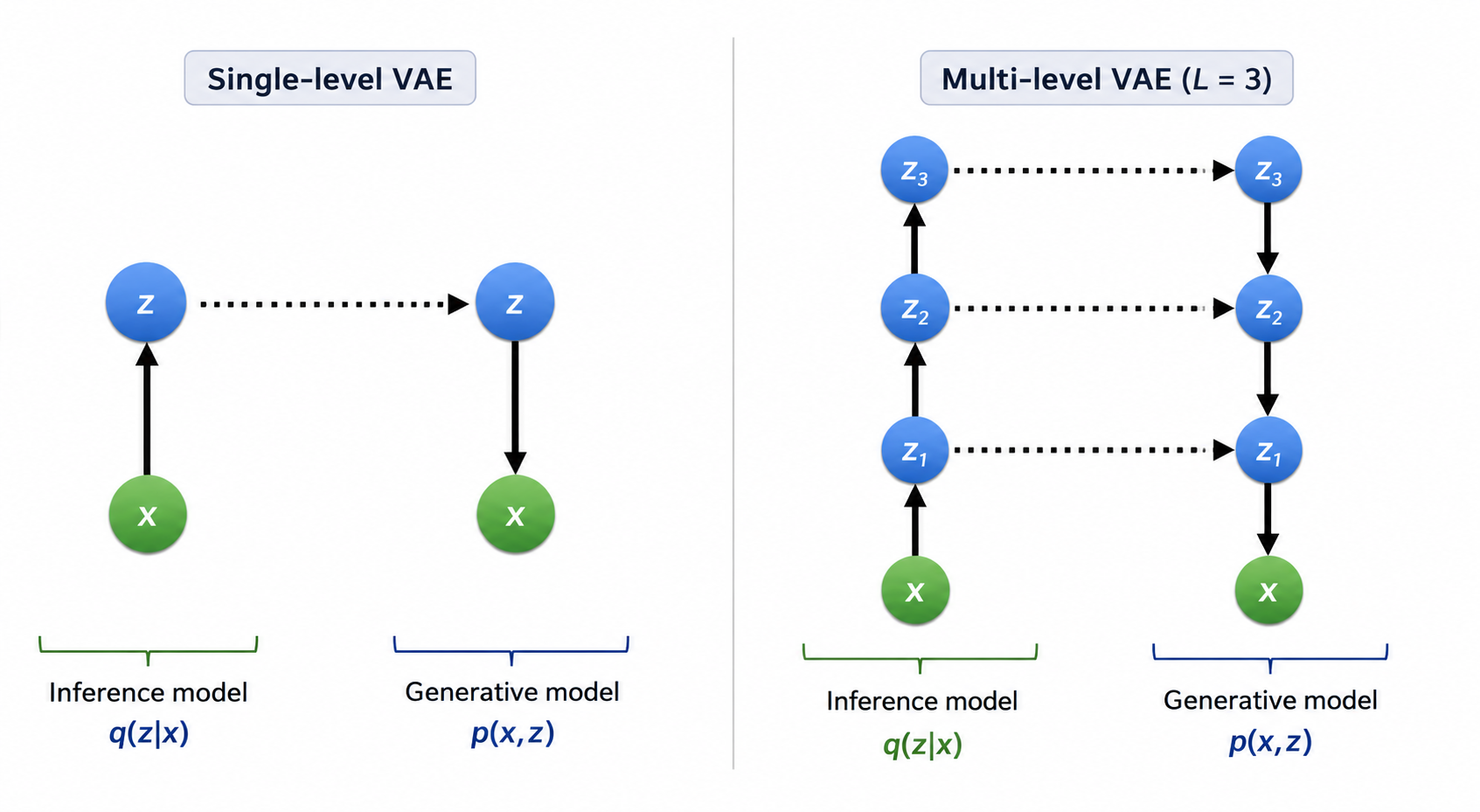
La distribución que se quiere modelar entonces es:
Por tanto, el ELBO se expresaría de la siguiente forma:
Se han publicado muchos trabajos que exploran diferentes tipos de modelos HVAE, entre los que destacan VD-VAE (Very Deep VAE)[child2020very] para generación de imágenes o Bit-swap[kingma2019bit] para compresión de datos.
La arquitectura de VD-VAE es un VAE convolucional simple. Para cada capa, el prior y el posterior son gaussianas diagonales. Descubrieron una técnica en la que el remuestreo del vecino más cercano (en el decoder) funcionaba mucho mejor que la convolución transpuesta y evitaba el posterior collapse. Esto permitió el entrenamiento con el ELBO original, sin necesidad de ninguno de los trucos discutidos anteriormente.
Extra: Compresión
En Bit-swap se presenta un VAE jerárquico con el que se demuestra que el esquema de compresión bits-back (BB-ANS) se puede usar con modelos de variables latentes. Es decir, este tipo de modelos generativos se pueden utilizar como esquemas de compresión eficientes. Veámoslo, pero primero: un poco de teoría de la información.
Complejidad de Kolmogórov
En teoría de la información, la complejidad de Kolmogórov de un objeto , denotada como , se refiere a la longitud de la descripción más corta posible de dicho objeto en un 'ordenador universal'. Representa la complejidad inherente de una pieza de información en función de la longitud del programa binario más conciso capaz de generarla.
Un programa binario más corto implica un mayor nivel de regularidad o predictibilidad en los datos.
Un programa binario más largo sugiere una estructura más compleja y menos compresible.
De manera similar, la complejidad de Kolmogórov de dado , , corresponde a la longitud del programa binario que, recibiendo como entrada, produce . A partir de esta idea, Bennett et al. [bennett1998information] derivaron la métrica de distancia de información, :
Esta métrica evalúa esencialmente la existencia de un programa sencillo capaz de transformar un objeto en otro y, por tanto, proporciona una medida de la relación o de la cantidad de información compartida entre ellos. Cuanto más simple sea el programa de conversión, más similares se consideran los objetos. Sin embargo, la complejidad de Kolmogórov no es computable teóricamente sino que solo puede aproximarse.
Compresión
Las técnicas de compresión aproximan la complejidad de Kolmogórov, ya que ofrecen un medio práctico para representar los datos de manera más concisa sin perder información esencial. El objetivo principal de un compresor sin pérdida (lossless compressor) es minimizar el número de bits necesarios para representar los datos, permitiendo posteriormente su decompresión exacta.
Los métodos de compresión logran este objetivo identificando y explotando redundancias o patrones presentes en los datos. Para alcanzar la menor longitud de compresión posible, los símbolos con mayor probabilidad reciben códigos más cortos. De acuerdo con el Teorema de Codificación de Fuentes de Shannon [shannon1948mathematical], la longitud de los bits codificados está directamente relacionada con la entropía de la fuente de información:
Lo que buscan los algoritmos de compresión es modelar eficazmente la distribución “real” de los datos :
-
Una estrategia habitual consiste en los métodos basados en diccionarios, donde se identifican patrones o secuencias de datos y se reemplazan por códigos más cortos. Entre ellos se encuentran los algoritmos de Lempel-Ziv, que construyen dinámicamente un diccionario durante la compresión [kosaraju2000compression].
-
Los modelos basados en contexto, como la codificación aritmética adaptativa, ajustan las probabilidades de codificación en función del contexto de los símbolos previamente codificados [moffat1998arithmetic].
-
Los métodos basados en transformaciones, como la ampliamente utilizada codificación de Huffman, reorganizan los datos en una forma más fácilmente compresible transformando la representación de los símbolos [moffat2019huffman].
Avances más recientes han incorporado técnicas de Machine Learning en los algoritmos de compresión, y qué tipo de modelos se puede utilizar para aproximar la distribución real de los datos?
Exacto, los VAEs!!
Modelos generativos como compresores
En un pipeline habitual de compresión, los datos se representan mediante una secuencia de símbolos y se codifican en un conjunto de bits . Posteriormente, se aplica el proceso inverso para recuperar los datos originales.
-
Compresión:
-
Decompresión:
Los métodos de compresión sin pérdida buscan minimizar el número de bits necesarios para representar un archivo sin sacrificar información. Los símbolos pertenecen a un conjunto finito y aparecen con probabilidades conocidas. La tasa óptima de compresión viene dada por la entropía de Shannon, donde representa la distribución de los datos y aproxima el número de bits requeridos para codificarlos.
Cuanto mejor sea la compresión, mejor será la aproximación de . En un contexto probabilístico, puede expresarse como la probabilidad de observar los datos bajo un modelo determinado:
donde es la probabilidad de observar los datos dado un conjunto específico de parámetros, es la distribución a priori y representa los parámetros del modelo.
En el contexto de un modelado generativo, esta expresión suele formularse en términos de la variable latente :
Te suena, no?
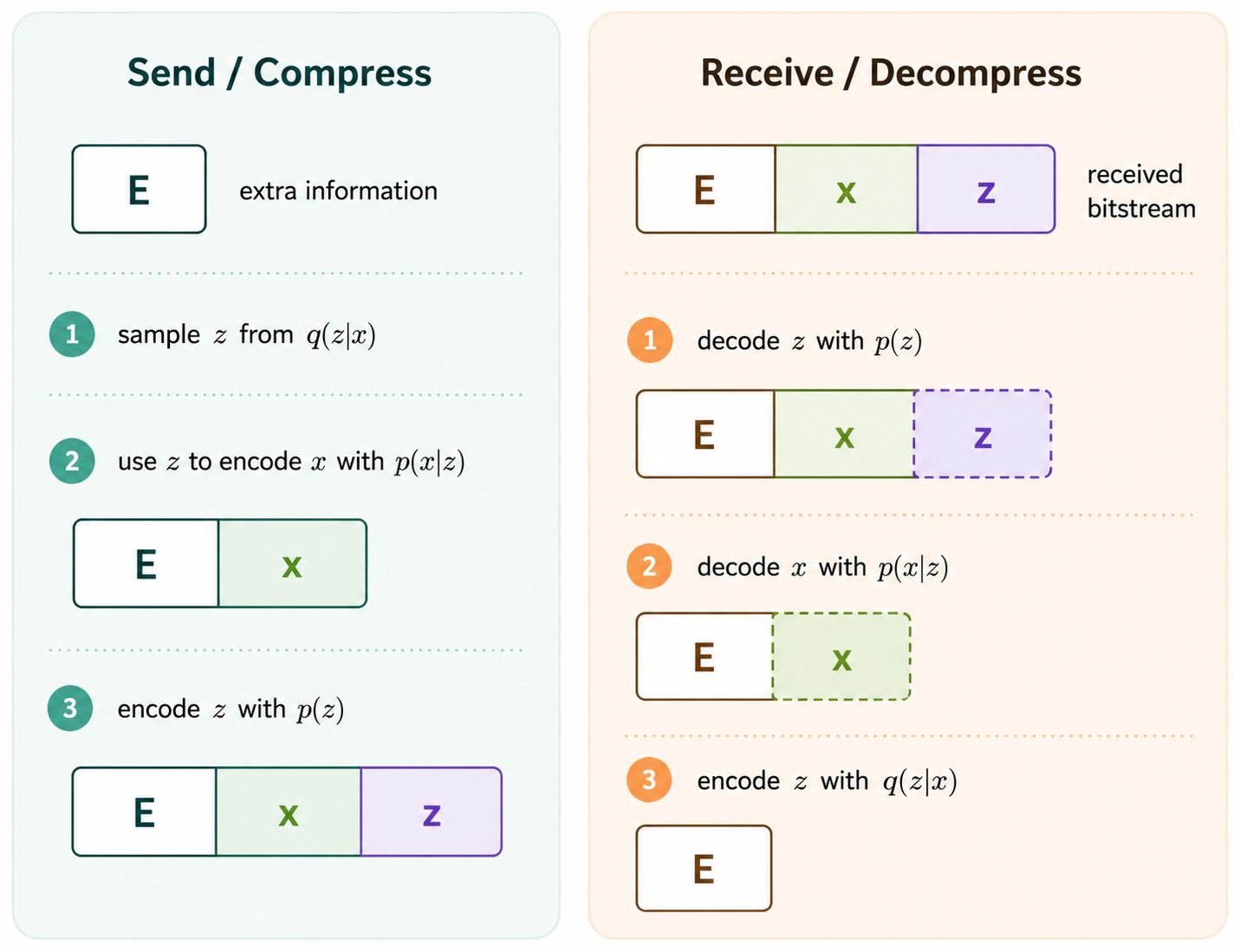
Utilizando esta notación, el proceso de envío de información en un esquema de compresión () se desarrolla de la siguiente manera:
- La variable latente se codifica utilizando .
- La muestra se codifica utilizando .
- Se transmiten tanto como .
Por otra parte, la recepción de la información () sigue estos pasos:
- se decodifica utilizando .
- se decodifica utilizando .
El número de bits involucrados en este proceso corresponde a la suma de los bits necesarios para transmitir y los necesarios para transmitir : y . Sin embargo, es posible transmitir algunos bits adicionales sin coste efectivo, concretamente , tal como describe el método bits-back [frey1997efficient]. Este concepto mantiene una estrecha relación con la inferencia variacional y los VAEs, como se ha mostrado en diversos trabajos previos [honkela2004variational], [chen2016variational].
El proceso de compresión descrito anteriormente puede interpretarse según el esquema BB-ANS [townsend2019practical]. Algunos bits adicionales se utilizan para generar una muestra mediante el encoder ; posteriormente, se emplea para codificar a través de , mientras que la propia variable se codifica usando la distribución a priori . El proceso inverso permite recuperar mediante , reconstruir mediante y recuperar los bits adicionales iniciales utilizando .
La longitud final del flujo de bits para un único dato viene dada por:
Fíjate que los términos y siguen transmitiéndose, pero los bits pueden recuperarse mediante el mecanismo bits-back. Lo relevante aquí es que coincide con el negativo de la (nEvidence Lower Bound, nELBO):
que corresponde precisamente con la función de pérdida utilizada en los VAEs!!
-
El primer término corresponde a la reconstrucción de y favorece a que el esquema de codificación/decodificación sea lo más eficiente posible maximizando utilizando muestras provenientes de .
-
El segundo término es la regularización del espacio latente mediante la minimización de la divergencia KL entre la aproximación variacional y la distribución a priori .
En consecuencia, minimizar el nELBO equivale simultáneamente a maximizar la probabilidad de generar datos reales, , y minimizar la divergencia KL entre y .
Esta equivalencia demuestra que un modelo de variables latentes correctamente optimizado, como un VAE, es directamente aplicable a tareas de compresión, ya que minimiza la longitud de código alcanzable en el contexto de la codificación bits-back.
Jiang et al., en NPC (Non-Parametric learning by Compression)[jiang2022few], propusieron un método basado en esta premisa para clasificación de imágenes, superando a métodos supervisados y semisupervisados.
De igual forma, en Few-shot generative compression approach for system health monitoring [costa2025few] propuse un método basado en compresión y VAEs para diagnosticar casos donde los datos de monitorización son abundantes, pero hay muy pocas instancias etiquetadas.