Redes GAN
"The most interesting idea in the last 20 years in Machine Learning" — Yann LeCun
Hasta la llegada de los Transformers y modelos de difusión, las Generative Adversarial Networks (Goodfellow et al., 2014) habían dominado ampliamente el panorama generativo, mostrando grandes avances en muchas tareas como la generación de imágenes, lenguaje natural y música.
En su día, se hicieron bastante famosas webs como thispersondoesnotexist y sus variantes. A día de hoy, estamos ya acostumbrados a ver imágenes realistas con IA, pero 'back in the day' impresionaba ver este tipo de imágenes y pensar que no eran humanos reales si no que habían sido generados por un modelo.
En la actualidad, las redes GANs ya no son la opción por defecto para la generación de contenido, pero sí siguen siendo utilizadas en nichos específicos y han sentado las bases para el posterior desarrollo de técnicas modernas de entrenamiento, como el aprendizaje por refuerzo humano (RLHF) en modelos de lenguaje.
Están inspiradas en la teoría de juegos: dos modelos, un generador y un discriminador, compiten y a la vez se mejoran entre sí.

Arquitectura
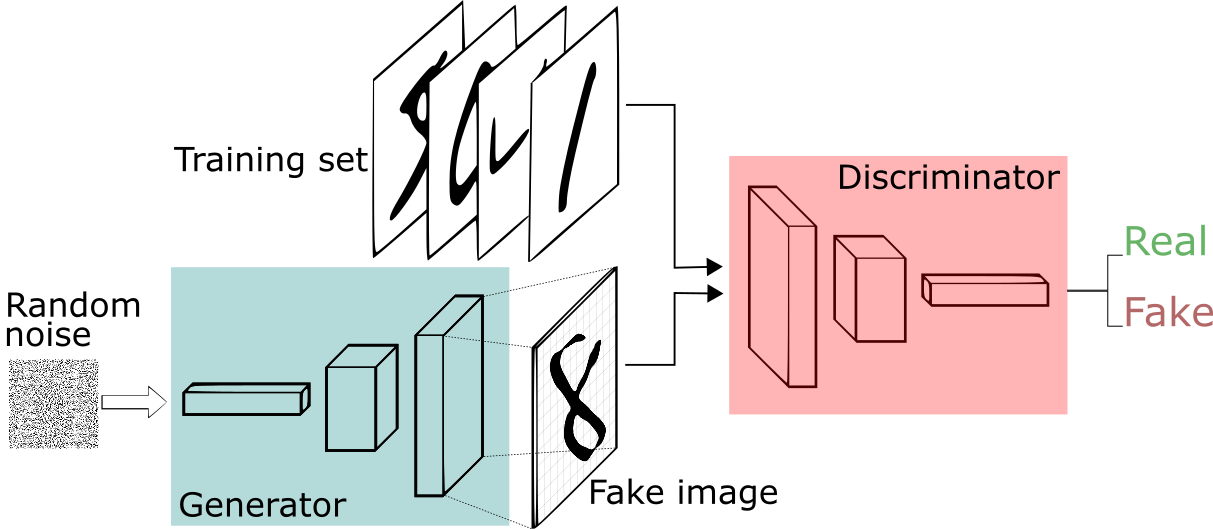
- Red generadora: recibe como entrada un vector de números aleatorio o ruido gaussiano (por eso a veces se le denomina ), a partir del cual se encarga de generar datos.
- Red discriminadora: su labor es identificar si los datos que recibe son reales (parte del conjunto de entrenamiento) o falsos (generados por la red generadora).
Explicación
La tarea de la discriminadora es diferenciar si las muestras que le llegan corresponden con la distribución de datos de entrenamiento (datos 'reales') o si por el contrario son muestras generadas por la generadora (datos 'falsos'). El objetivo de la generadora, por tanto, es producir muestras lo más realistas posibles para intentar engañar a la discriminadora.
Al principio del entrenamiento, ninguna de las redes es buena en su tarea. La generadora produce imágenes borrosas y sin coherencia y la discriminadora no es buena discerniendo entre datos reales o falsos.
Sin embargo, a medida que avanza el entrenamiento la generadora va produciendo mejores ejemplos para intentar engañar a la discriminadora y la discriminadora, al ver más datos reales, va aprendiendo la distribución real de los datos, por lo que entran en un juego de suma 0 en el que al final del proceso ambas redes son muy buenas en sus tareas.
Normalmente, tras el entrenamiento la discriminadora se desecha, ya que el interés principal está en la generación de datos. Sin embargo, la discriminadora es un buen clasificador binario que se podría utilizar para otras tareas.
Aplicaciones
El área de aplicación más estudiada y popularmente conocida es la generación de imágenes. Aquí algunas aplicaciones:
- Conditional image generation: por ejemplo, BigGAN[brock2018large] puede generar muestras de ImageNet condicionadas a una clase concreta. StyleGAN[karras2019style] es capaz de generar imágenes de caras en alta resolución condicionadas a características concretas: aprende un embedding para luego interpolar entre diferentes características como peinado, gafas de sol, arrugas…
- Paired image-to-image generation: se pueden utilizar datos en la forma para construir modelos generativos condicionales . En algunos casos, la variable condicionante tiene la misma dimensión que la variable de salida . El modelo resultante se puede utilizar entonces para realizar la traslación de imagen a imagen,un proceso donde se aprende un mapeo entre dos dominios visuales. Un ejemplo de esto sería la colorización, donde el modelo toma una foto en blanco y negro y "rellena" los colores basándose en los patrones que ha aprendido, o la segmentación, donde el modelo convierte un esquema de etiquetas de colores (como un plano donde cada color es un objeto) en una fotografía realista que respeta exactamente esas formas.
- Unpaired image-to-image generation: una limitación de las GAN condicionales es la dificultad para recopilar datos emparejados. Es mucho más fácil recopilar datos no emparejados, por ejemplo, un conjunto de imágenes diurnas y un conjunto de imágenes nocturnas . Suponemos que los conjuntos y proceden de las distribuciones marginales y respectivamente. El objetivo es ajustar un modelo conjunto de modo que podamos calcular los condicionales y y así traducir de un dominio a otro. Esto se denomina unsupervised domain translation y tiene aplicaciones como la transferencia de estilos.

Aplicaciones en otros dominios
- Generación de vídeo: la coherencia espacio-temporal se obtiene garantizando que el discriminador tenga acceso a los datos reales y a las secuencias generadas en orden, penalizando así al generador cuando genera fotogramas individuales realistas sin respetar el orden temporal.
- Generación de audio: se han desarrollado muchas arquitecturas GAN diferentes para la generación de audio, incluyendo la generación de grabaciones de instrumentos por GANSynth[engel2019gansynth], la conversión de voz[kaneko2020cyclegan] y la generación directa de audios en WaveGAN[donahue2018adversarial].
- Generación de texto: existen varias tareas para datos de texto para las que se han desarrollado enfoques basados en GAN, como la generación de texto condicional y la transferencia de estilo de texto. Los datos de texto suelen representarse como valores discretos (a nivel de caracteres o de palabras), que indican la pertenencia a un conjunto de un determinado vocabulario.
- Domain adaptation: una tarea importante en machine learning es corregir los cambios en la distribución de los datos, ya que en muchas ocasiones la distribución donde se evalúa el modelo en inferencia no es exactamente igual a la distribución de los datos de entrenamiento. En general, los enfoques para la generación de imágenes mencionados se centran en adaptaciones a nivel de píxel, como pix2pix[isola2017image]. Sin embargo, las extensiones de estos enfoques para el problema general de adaptación de dominio buscan hacerlo no sólo en el espacio de datos observado, sino también a nivel de características.
Función de error
Por un lado, queremos que el discriminador se convierta en un experto identificando lo que es real y lo que es falso. Esto lo hacemos mediante:
- Identificar lo real: Se maximiza , obligando al discriminador a asignar una probabilidad cercana a 1 a cualquier dato que provenga del conjunto real.
- Identificar lo falso: Se maximiza , obligando al discriminador a asignar una probabilidad cercana a 0 a cualquier dato generado por G.
Por otra parte, el generador se entrena para aumentar las posibilidades de producir una alta probabilidad para un ejemplo falso y así minimizar .
Al combinar ambas partes, estamos jugando a un juego 'minimax' en el que debemos optimizar la siguiente función de pérdida:
Limitaciones
Aunque las GAN han demostrado un gran éxito en la generación de imágenes realistas, el entrenamiento no es fácil: es un proceso lento e inestable.
Cada modelo actualiza su coste de forma independiente sin tener en cuenta al otro "jugador". La actualización simultánea del gradiente de ambos modelos no garantiza la convergencia. Esto en ocasiones puede desembocar en el mode collapse. Durante el entrenamiento, el generador puede colapsar a una configuración en la que siempre produce las mismas salidas. Aunque el generador sea capaz de engañar al discriminador correspondiente, no consigue aprender a representar la compleja distribución de datos del mundo real y se queda atascado en un espacio pequeño con una variedad extremadamente baja.
El entrenamiento de una GAN se enfrenta a un dilema:
- Si el discriminador no es bueno, el feedback que recibe el generador tampoco es bueno y en consecuencia la función de pérdida no representa la realidad (causando que el generador no consiga modelar bien la distribución de datos reales).
- Si el discriminador es muy bueno, el gradiente de la función de pérdida cae hasta cerca de cero y el aprendizaje se vuelve lento o incluso se atasca (vanishing gradient).