Flow-based Models
Modelos generativos como las redes GAN o los VAE no aprenden explícitamente la función de densidad de los datos, .
Como ya vimos, esto es entendible: si tomamos como ejemplo un modelo generativo típico con variables latentes,
difícilmente se puede llegar a computar de forma explícita porque es prácticamente imposible recorrer todos los valores de .
Flow-based models
Los flow-based models aproximan este problema por medio de los Normalizing Flows (y Flow Matching, pero lo veremos más adelante), un método que permite la estimación de densidad de los datos.
Una buena estimación de hace posible realizar eficientemente muchas tareas como muestrear nuevos puntos de datos no observados pero realistas (generación de datos), permitir detectar datos fuera de distribución (OOD), inferir variables latentes, rellenar muestras de datos incompletas, etc.
Normalizing flows
Dado que para entrenar modelos de aprendizaje profundo utilizamos backpropagation, se espera que la distribución de probabilidad a posteriori sea lo suficientemente simple como para calcular la derivada de forma fácil y eficiente. Por eso se suele utilizar la distribución gaussiana en los modelos generativos de variables latentes, aunque la mayoría de las distribuciones del mundo real sean mucho más complicadas que la gaussiana.
Un normalizing flow transforma una distribución simple en una compleja aplicando una secuencia de funciones de transformación invertibles. "Fluyendo" a través de una cadena de transformaciones, se sustituye repetidamente la variable por la nueva para finalmente obtener una distribución de probabilidad acorde a la variable objetivo final.
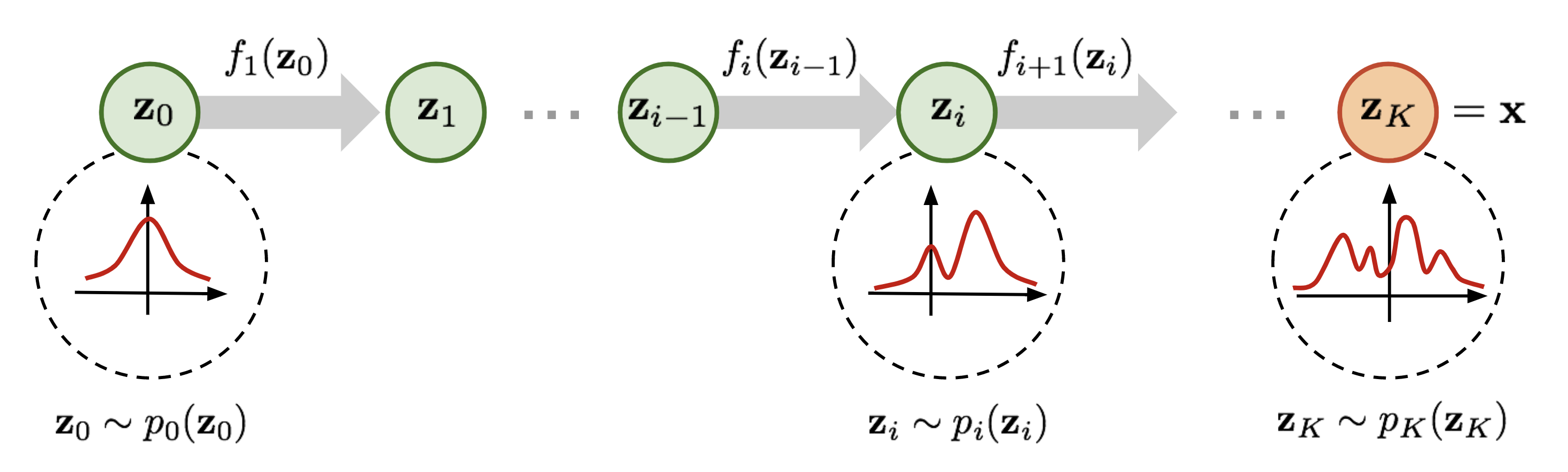
Tanto la transformación directa como su inversa se pueden calcular exactamente. Esto permite realizar la estimación de densidad. Para ello, se deben tener en cuenta dos cosas:
- La densidad de la muestra transformada inversamente: para obtener la muestra transformada, se aplica la secuencia de transformaciones inversas a la muestra original. Luego, se evalúa la densidad de esta muestra transformada bajo la distribución simple original. Es decir, se comprueba si la transformación resultante es una Normal.
- El cambio de volumen debido a las transformaciones: a medida que se realizan las transformaciones, el espacio de la muestra se distorsiona. El cambio de volumen se calcula multiplicando los valores absolutos de los determinantes de las matrices jacobianas de cada transformación.
Multiplicando estos dos valores (la densidad de la muestra transformada y el cambio de volumen), se obtiene la densidad de la muestra original bajo la distribución compleja.
Aplicaciones
Las aplicaciones más directas de los normalizing flows son:
- Estimación de densidad: para calcular la densidad exacta de los datos. Se pueden aplicar para ajustar densidades multimodales a los datos observados. También pueden utilizarse como modelos híbridos que modelan la densidad conjunta de entradas y objetivos , a diferencia de los modelos de clasificación que sólo modelan y los modelos de densidad que sólo modelan . Esto es útil para tareas como la detección de anomalías.
- Generación de datos: para diferentes modalidades de datos, incluyendo imágenes, vídeo, audio, texto y objetos estructurados como grafos y nubes de puntos.
- Inferencia: para modelar distribuciones posteriores variacionales en modelos de variables latentes. También se pueden utilizar para guiar simulaciones con el fin de hacer la inferencia más eficiente. Este enfoque se ha utilizado para la inferencia de modelos de simulación en cosmología[alsing2019fast] y neurociencia computacional[gonccalves2019training].
Conceptos básicos de álgebra lineal
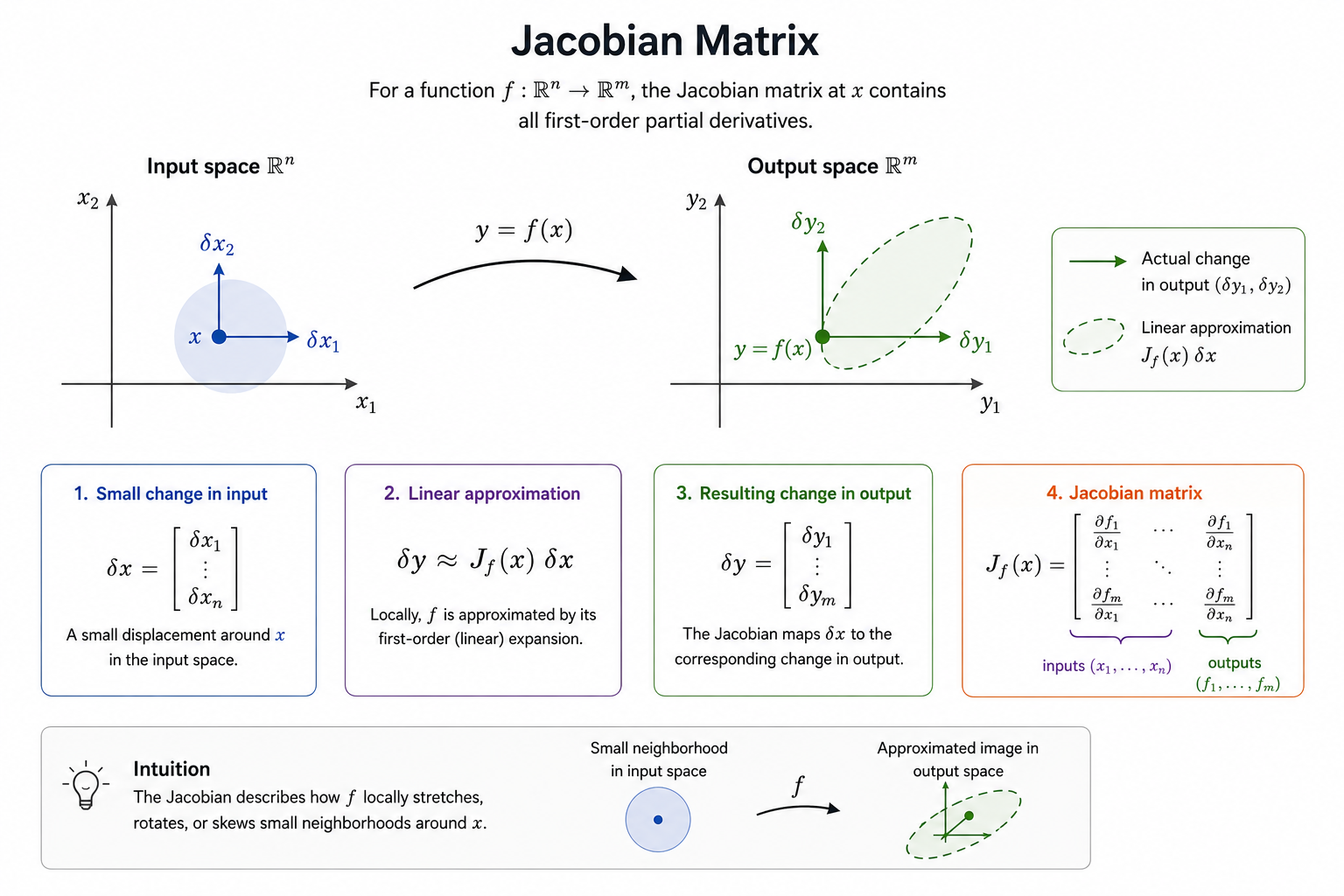
Matriz jacobiana
Dada una función de mapeo de un vector de entrada -dimensional a un vector de salida -dimensional, la matriz de todas las derivadas parciales de primer orden de esta función se denomina matriz jacobiana:
Se puede entender como un traductor de un espacio vectorial a otro.
Determinante
El valor absoluto del determinante (sólo existe para matrices cuadradas) puede considerarse como una medida de "cuánto expande o contrae el espacio la multiplicación por la matriz".
El determinante de una matriz cuadrada detecta si es invertible:
-
si entonces no es invertible (una matriz singular con filas o columnas linealmente dependientes; o cualquier fila o columna toda 0);
-
si , entonces es invertible.
El determinante del producto es equivalente al producto de los determinantes: .
Teorema del cambio de variable
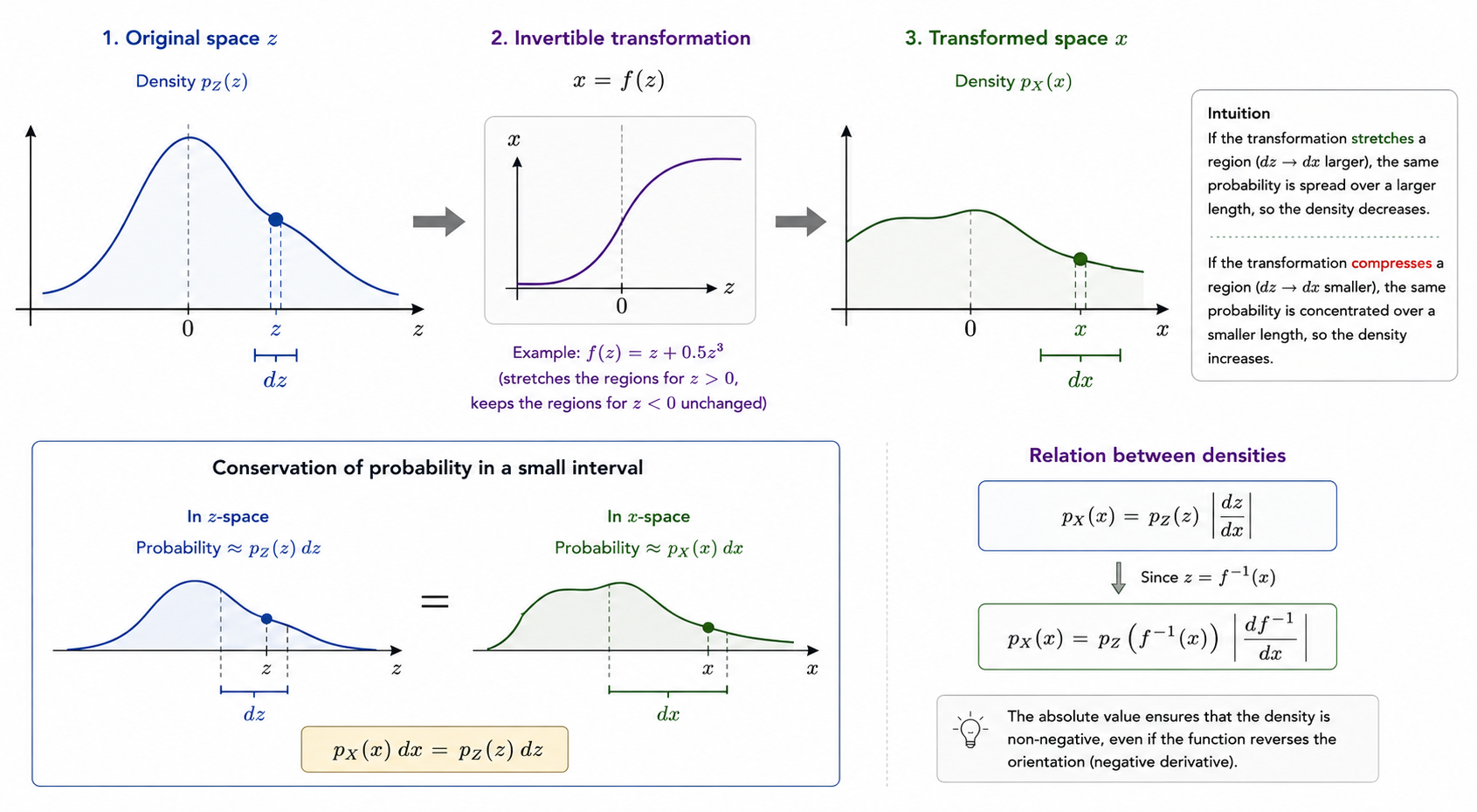
Cuando transformamos una variable aleatoria, su probabilidad no cambia, pero el espacio donde vive sí puede estirarse o comprimirse.
Imagina una variable sencilla con densidad conocida , por ejemplo una normal. Ahora aplicamos una función invertible:
Como es invertible, si conocemos un valor de también podemos recuperar el valor de que lo produjo:
La pregunta es: si conocemos la densidad en el espacio original, , ¿cómo calculamos la densidad en el nuevo espacio, ?
Así de primeras se podría pensar que es:
Esto nos dice de dónde viene , pero se deja una cosa fuera: la transformación puede haber cambiado el tamaño de las regiones del espacio.
En una dimensión, podemos pensarlo con intervalos pequeños. Un trocito alrededor de tiene longitud . Después de aplicar la transformación, ese trocito se convierte en otro alrededor de con longitud .
La probabilidad dentro de ambos trocitos debe ser la misma:
Reordenando:
Y como :
El valor absoluto aparece porque una densidad no puede ser negativa. Si la función invierte el eje, por ejemplo de izquierda a derecha, la derivada puede ser negativa, pero el factor de cambio de tamaño sigue siendo positivo.
En varias dimensiones ocurre lo mismo, pero los "trocitos" ya no son intervalos, sino pequeñas áreas, volúmenes o hipervolúmenes. Ahí entra el determinante jacobiano:
Donde es la matriz jacobiana de la función inversa. Su determinante mide cuánto se expande o contrae localmente el volumen al pasar de de vuelta a .
También se suele escribir usando la transformación directa :
Esta forma es equivalente. Si estira el volumen por un factor , entonces la densidad se divide por . Si lo comprime por un factor , entonces la densidad se multiplica por .
Aplicación a normalizing flows
Un normalizing flow no hace una única transformación, sino una cadena de transformaciones invertibles:
Normalmente empezamos con una distribución fácil:
Después aplicamos transformaciones hasta llegar a una muestra con aspecto de dato real:
Esto sirve para generar datos: muestreamos un sencillo y lo vamos transformando hasta obtener .
Pero lo interesante de los flows es que también podemos hacer el camino inverso para calcular la densidad exacta de un dato :
Una vez tenemos , su densidad es fácil de calcular porque pertenece a la distribución simple. Lo único que falta es corregir todos los cambios de volumen que se han producido por el camino.
Para una sola transformación:
Aplicando el teorema del cambio de variable:
Esta ecuación dice:
- la densidad después de la transformación depende de la densidad antes de la transformación;
- si la transformación expande el espacio, la densidad baja;
- si la transformación comprime el espacio, la densidad sube.
Como comentamos en el capítulo de las GAN, en Machine Learning solemos trabajar con logaritmos de probabilidades debido a que:
- los productos de muchos números pequeños tienden a cero;
- los productos se convierten en sumas, que son más fáciles de optimizar.
Tomando logaritmos:
Si repetimos esto para las transformaciones del flow, obtenemos:
Esta es la fórmula central de los normalizing flows.
Se lee así:
- : la log-densidad del dato real que queremos evaluar;
- : la log-densidad del punto correspondiente en la distribución simple;
- : la corrección acumulada por todos los cambios de volumen introducidos por las transformaciones.
El camino recorrido por las variables aleatorias es el flujo. La cadena completa de distribuciones sucesivas es lo que llamamos normalizing flow.
Modelos basados en Normalizing flows
Algunas arquitecturas populares de normalizing flows son Real NVP[dinh2016density], Masked Autoregressive Flows[papamakarios2017masked], Glow[kingma2018glow] (por Kingma autor del paper del VAE original y creador del optimizador Adam), SurVAE[nielsen2020survae] (mezcla de VAEs y normalizing flows).
Las diferencias entre estas arquitecturas residen en las transformaciones que aplican y en diseños de red específicos, pero todas comparten el objetivo común de transformar una distribución simple en una más compleja.
Ventajas y desventajas
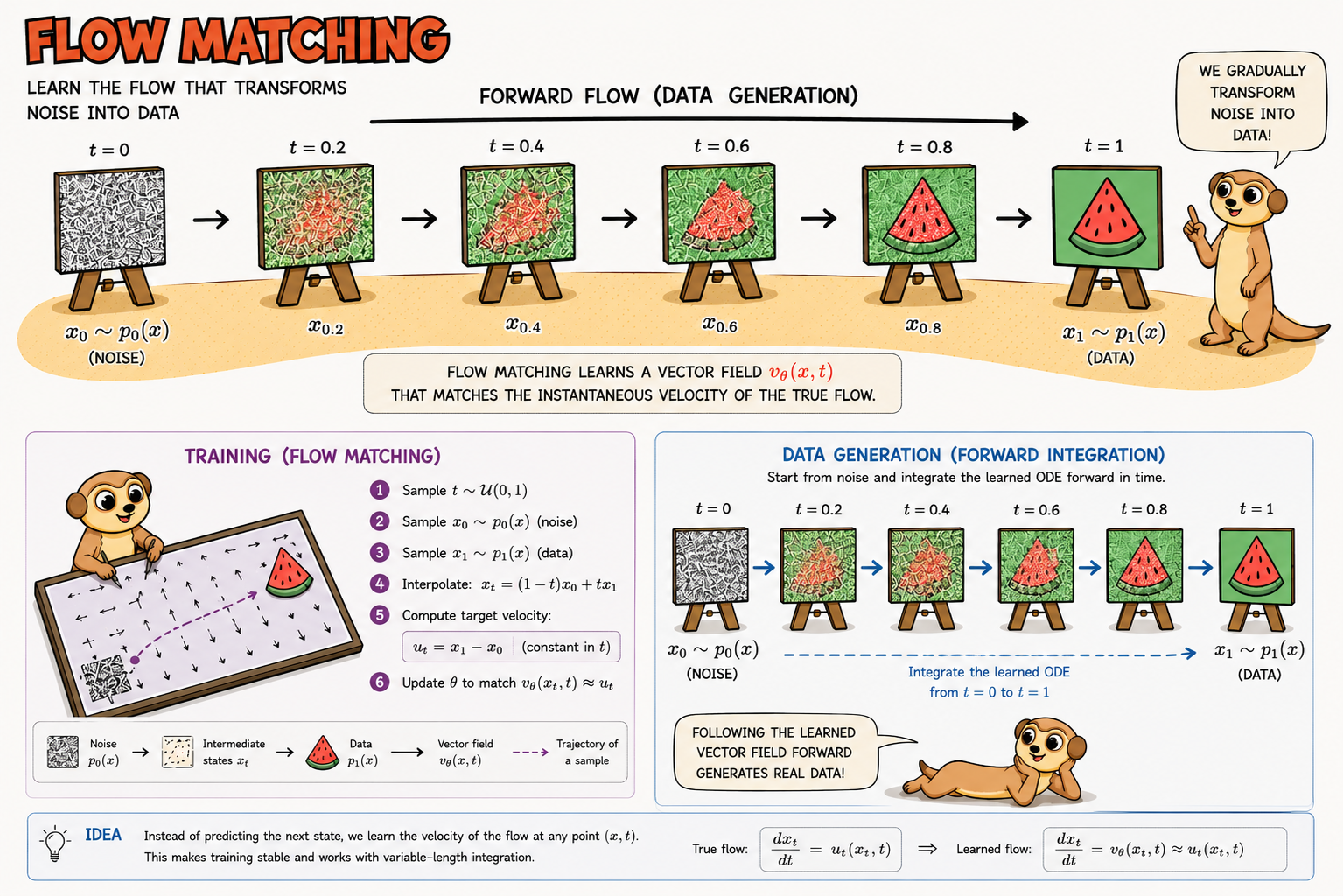
Flow Matching
Como hemos visto, los normalizing flows construyen el modelo como una cadena de transformaciones invertibles:
Flow Matching parte de una idea parecida, pero cambia la pregunta.
En vez de preguntar:
¿Qué transformaciones invertibles puedo diseñar para convertir ruido en datos?
pregunta:
¿Qué dirección debería seguir cada punto para moverse desde una distribución simple hasta la distribución objetivo?
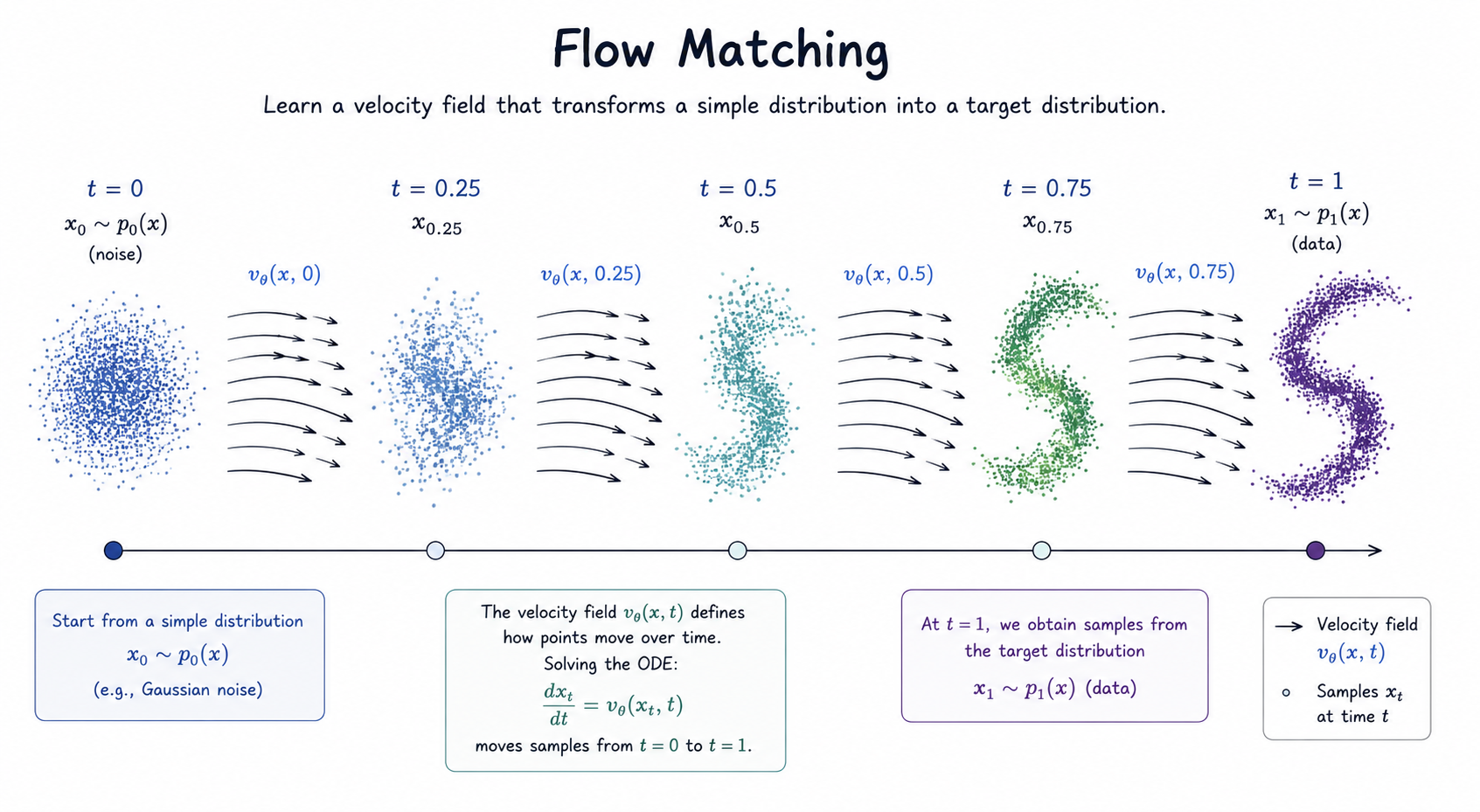
Es decir, Flow Matching aprende un campo de velocidades.
Un campo de velocidades
Imagina que tenemos muchos puntos de ruido, por ejemplo muestras de una normal, y muchos puntos reales, por ejemplo imágenes. Queremos mover poco a poco los puntos de ruido hasta que acaben pareciéndose a los datos reales.
Para describir ese movimiento introducimos una variable de tiempo:
Cuando , estamos en la distribución simple:
Cuando , queremos estar en la distribución de datos:
Entre medias tenemos puntos intermedios . El modelo aprende una función:
Esta función recibe dos cosas:
- el punto actual ;
- el tiempo actual .
Y devuelve un vector que indica hacia dónde debería moverse ese punto en ese instante.
Cómo se entrena
Para entrenar el modelo necesitamos saber cuál sería una buena velocidad en distintos puntos intermedios. Una forma sencilla de verlo es emparejar un punto de ruido con un dato real y trazar una línea entre ambos:
Esta ecuación solo dice que es una interpolación:
- si , entonces ;
- si , entonces ;
- si está entre 0 y 1, entonces está entre el ruido y el dato.
Si el camino es una línea recta, la velocidad que lleva de a es:
Por tanto, durante el entrenamiento podemos hacer lo siguiente:
- Tomamos una muestra de ruido .
- Tomamos un dato real .
- Elegimos un tiempo aleatorio entre 0 y 1.
- Construimos el punto intermedio .
- Pedimos a la red que prediga la velocidad correcta .
La función de pérdida puede escribirse como:
Aunque la fórmula pueda parecer densa, la idea es bastante directa: la red predice una flecha, y la penalizamos si esa flecha apunta en una dirección distinta de la que debería.
Cómo se generan nuevas muestras
Una vez entrenado el modelo, generar una muestra consiste en resolver una ecuación diferencial ordinaria (ODE):
Esto significa: "actualiza siguiendo la velocidad que predice la red en cada instante".
En la práctica:
- Muestreamos un punto inicial de ruido .
- Evaluamos la red para saber hacia dónde moverlo.
- Damos un pequeño paso en esa dirección.
- Repetimos el proceso desde hasta .
Al final obtenemos , que debería parecer una muestra de la distribución de datos.
Diferencia con Normalizing Flows
Normalizing flows y Flow Matching comparten una intuición: ambos transforman una distribución simple en una distribución compleja. La diferencia está en cómo lo hacen.
En normalizing flows:
- usamos una secuencia finita de transformaciones invertibles;
- calculamos cómo cambia la densidad con determinantes jacobianos;
- podemos evaluar la densidad exacta de los datos de forma natural.
En Flow Matching:
- aprendemos un campo de velocidades continuo;
- generamos datos siguiendo una trayectoria desde ruido hasta datos;
- no necesitamos diseñar manualmente capas invertibles con determinantes fáciles.
Por eso Flow Matching resulta atractivo: permite usar redes neuronales más flexibles y entrenarlas con una pérdida de regresión relativamente simple.
Optimal Transport como ampliación
Una vez entendida la idea central de Flow Matching, tiene sentido hablar de Optimal Transport como una forma de elegir mejores caminos entre la distribución inicial y la distribución de datos.
La intuición de Optimal Transport es transformar una distribución en otra pagando el menor coste posible.
En Flow Matching esto aparece cuando construimos caminos entre puntos de ruido y puntos reales. Si emparejamos puntos al azar, las trayectorias pueden cruzarse mucho o dar rodeos innecesarios. Si usamos una idea de transporte óptimo, intentamos emparejar puntos de forma más coherente.
Por eso en la literatura aparecen variantes como Optimal Transport Flow Matching u OT-CFM. El paper original de Flow Matching for Generative Modeling ya destaca el uso de caminos basados en transporte óptimo como una opción especialmente interesante, y trabajos posteriores como Improving and Generalizing Flow-Based Generative Models with Minibatch Optimal Transport usan transporte óptimo en mini-batches para construir emparejamientos más útiles durante el entrenamiento.
Lo importante es no confundir los niveles:
- Flow Matching: aprende un campo de velocidades que mueve muestras desde ruido hacia datos.
- Optimal Transport: puede ayudar a definir caminos o emparejamientos más eficientes para entrenar ese campo de velocidades.
Relación con los modelos de difusión
Flow Matching está muy relacionado con los modelos de difusión, porque ambos describen un proceso que conecta ruido con datos.
La diferencia intuitiva es:
- en difusión, normalmente se aprende a invertir un proceso que va añadiendo ruido poco a poco;
- en Flow Matching, se aprende directamente el campo de velocidades que transporta las muestras desde ruido hasta datos.
La forma matemática de formular esa dirección cambia, pero la intuición de fondo es muy parecida.
Lo veremos en el siguiente capítulo.