Diffusion-based Models
Introducción
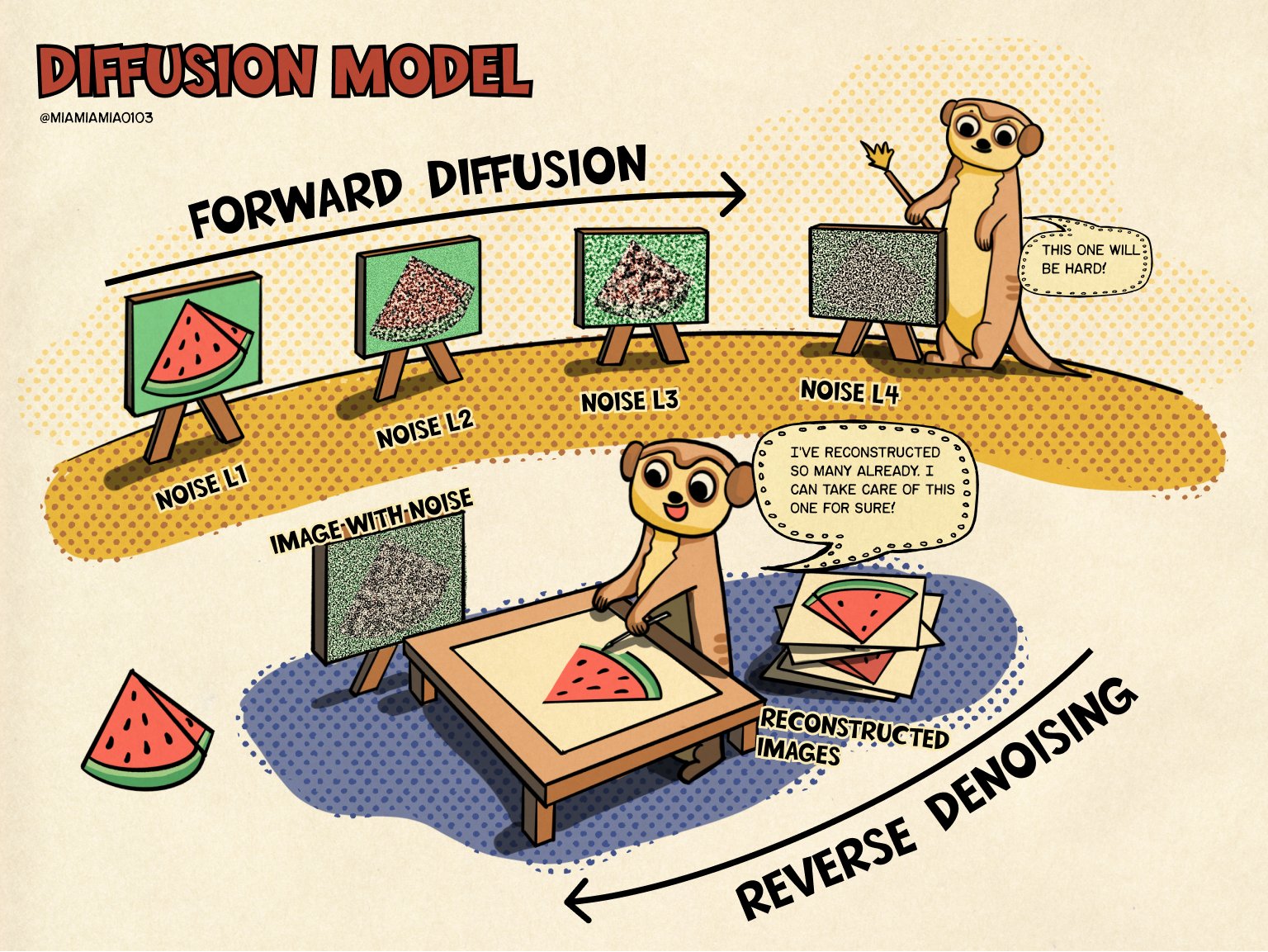
Los modelos de difusión se inspiran en la termodinámica del no equilibrio. Añaden ruido a los datos para después aprender a invertir el proceso para reconstruir las muestras a partir del ruido.
La intuición es muy visual: partimos de una imagen real, le añadimos un poco de ruido, luego un poco más, y así sucesivamente hasta que prácticamente solo queda ruido. Después entrenamos una red neuronal para hacer el camino contrario: mirar una imagen ruidosa y decir qué parte de esa imagen parece ruido para poder retirarlo.
En concreto, se puede aplicar un proceso de difusión para convertir gradualmente los datos observados en una versión con ruido haciendo pasar los datos a través de pasos de un encoder estocástico . Después de suficientes pasos, se tendrá , o cualquier otra distribución de referencia conveniente. Después, se aprende un proceso inverso para deshacer este proceso, pasando el ruido a través de pasos de un decoder hasta generar de nuevo.
Recuerdas la imagen del principio del curso? Ahora debería quedar mucho más clara.
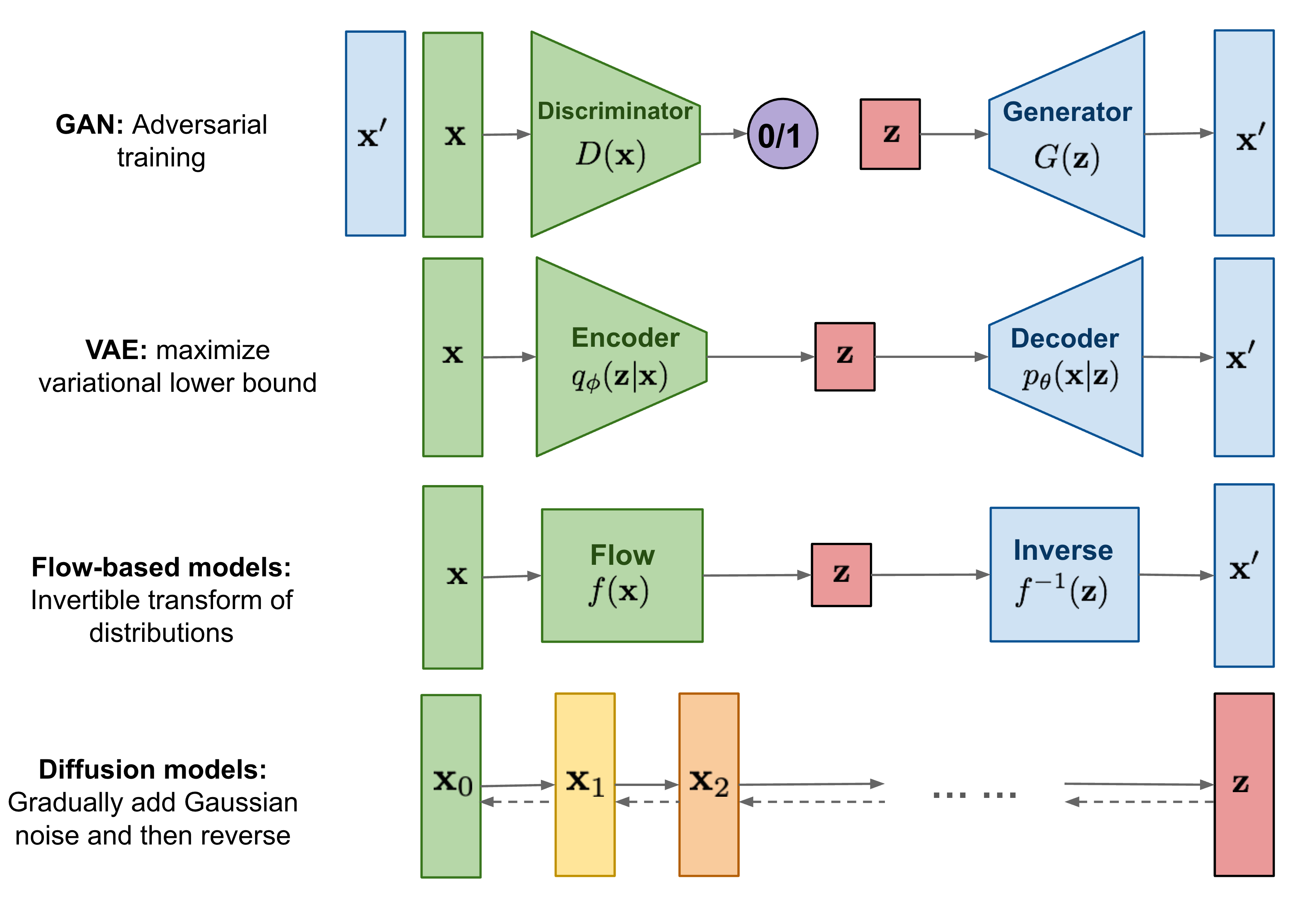
En los modelos de difusión el encoder se no se aprende si no que sigue un procedimiento fijo y la variable latente tiene la misma dimensionalidad que los datos originales (a diferencia de los VAEs). Por otro lado, el decoder se comparte en todos los pasos. Estas condiciones dan lugar a una función de error simple, que facilita el entrenamiento y evita el riesgo del posterior collapse.
Varios modelos generativos basados en difusión han sido propuestos, incluidos diffusion probabilistic models[sohl2015deep], noise-conditioned score network[song2019generative], denoising diffusion probabilistic models[ho2020denoising] y variational diffusion models[kingma2021variational].
Encoder (forward diffusion)
El forward diffusion es la parte fácil porque no se aprende: nosotros decidimos cómo añadir ruido. Es un procedimiento fijo.
El proceso de codificación hacia delante se define como un modelo lineal gaussiano simple:
donde los valores de se eligen según un noise scheduler.
Intuitivamente, controla cuánto ruido añadimos en el paso :
- si es pequeño, la imagen cambia muy poco;
- si es grande, añadimos mucho ruido de golpe.
El noise scheduler decide cómo crece esa cantidad de ruido a lo largo del proceso. No es lo mismo añadir mucho ruido desde el principio que añadirlo lentamente y acelerar al final.
La distribución conjunta sobre los estados latentes es:
La distribución se conoce como diffusion kernel. Aplicar esto a la distribución de datos de entrada y luego calcular los marginales incondicionales resultantes es equivalente a la convolución gaussiana:
A medida que aumenta, los marginales se vuelven más simples. En imágenes, este proceso primero eliminará el contenido de alta frecuencia (es decir, detalles de bajo nivel, como la textura), y luego eliminará el contenido de baja frecuencia (información de alto nivel o "semántica", como la forma).

Decoder (reverse diffusion)
El objetivo final de un modelo de difusión es que el proceso inverso (decoder) aprenda la distribución de datos originales, .
- Proceso gradual: al añadir ruido en pasos pequeños, se crea una secuencia de distribuciones intermedias , donde es el dato original con una cantidad creciente de ruido.
- El proceso progresivo descompone una tarea de generación muy compleja en una secuencia de tareas de denoising más sencillas y manejables.
Esta es la clave práctica: generar una imagen completa desde cero es difícil, así que reformulamos el problema: ahora lo que queremos es 'únicamente' quitar un poco de ruido de una imagen ruidosa. Al hacerlo en varios pasos, convertimos una tarea complicada en muchas tareas pequeñas.
En otras palabras, en el proceso de difusión inverso queremos invertir el proceso:
- Si se conoce la entrada , se puede calcular la inversa matemáticamente.
- Si se quiere generar un nuevo punto de datos, aunque no se conozca , se entrena al generador/decoder para que se aproxime a la distribución de los datos sobre el proceso inverso. Por lo tanto, sigue la forma:
La distribución conjunta correspondiente sobre todas las variables generadas está dada por:
Para generar datos a partir del modelo, se muestrea un punto y luego se ejecuta la cadena de Markov hacia atrás, muestreando hasta obtener una muestra en el espacio de datos original, .
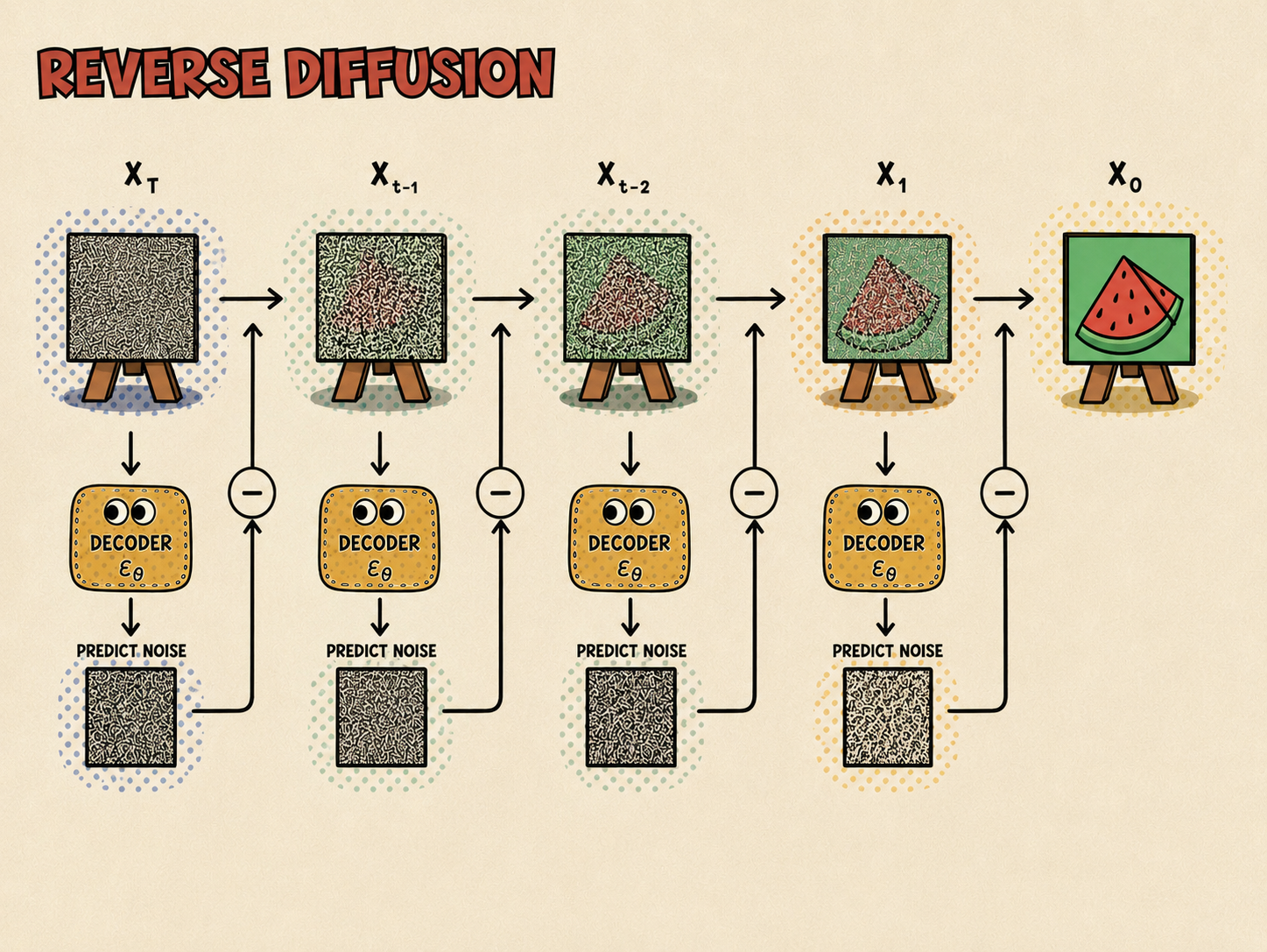
Model fitting
Los modelos de difusión, al igual que los VAE, pueden utilizar el ELBO como función de error. En este contexto, el ELBO es una suma de términos que corresponden a la divergencia KL entre las distribuciones de ruido añadido en cada paso del proceso hacia delante y las distribuciones predichas por el proceso inverso. Al optimizar este ELBO, el modelo aprende a invertir el proceso de adición de ruido, aprendiendo efectivamente a eliminar el ruido de los datos en cada paso.
En lugar de entrenar el modelo para predecir la imagen con ruido anterior dado , se entrena el modelo para predecir el ruido que hay en .
Es decir, durante el entrenamiento hacemos algo así:
- Tomamos una imagen real .
- Elegimos un paso aleatorio .
- Añadimos una cantidad conocida de ruido para obtener .
- Le damos al modelo.
- El modelo intenta predecir el ruido que hemos añadido.
Como nosotros hemos añadido el ruido, sabemos cuál es la respuesta correcta. Por eso podemos entrenar el modelo con una pérdida sencilla, normalmente un error cuadrático entre el ruido real y el ruido predicho:
Aquí es el ruido real añadido y es el ruido que predice la red.
Los modelos de difusión están estrechamente relacionados con el score matching, una técnica en la que el modelo aprende el gradiente (score) de la densidad de datos logarítmica. El ELBO proporciona un método para estimar los parámetros del proceso inverso, que está relacionado con el score matching en el sentido de que se aprende la función de puntuación del proceso inverso.
Maximizar el ELBO equivale a minimizar la diferencia entre la distribución real de los datos y la distribución del modelo tras el proceso de difusión inverso. El ELBO suele incluir:
- Un término de reconstrucción que asegura que el modelo pueda reconstruir los datos a partir de una versión ruidosa.
- Un término de regularización (divergencia KL) que garantiza que el ruido añadido en el proceso hacia delante sigue la distribución esperada.
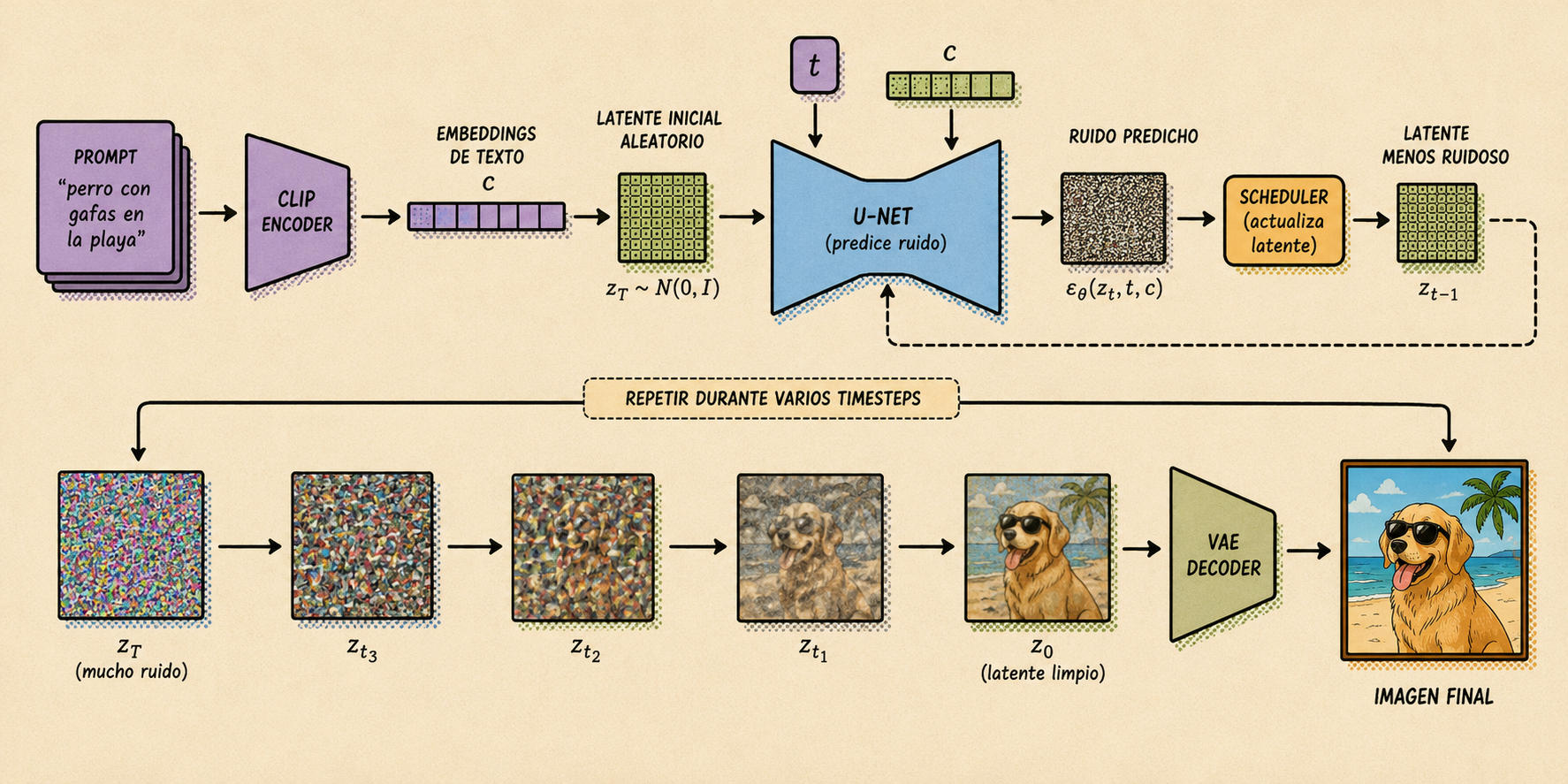
Ejemplo: Stable Diffusion
Stable Diffusion es uno de los modelos más icónicos que aplicaron la idea de difusión. Uno de los motivos en el salto de calidad en generación de imágenes respecto a modelos anteriores fue que la difusión no se hace directamente sobre los píxeles de la imagen si no que se hace sobre el espacio latente.
Esto lo convierte en un latent diffusion model.
La motivación es muy práctica. Una imagen de con 3 canales tiene una dimensionalidad muy grande, por lo que hacer difusión sobre todos esos píxeles es caro. Stable Diffusion primero comprime la imagen a una representación más pequeña, realiza el proceso de denoising en ese espacio comprimido y, al final, decodifica el resultado para volver a píxeles.
Visión general
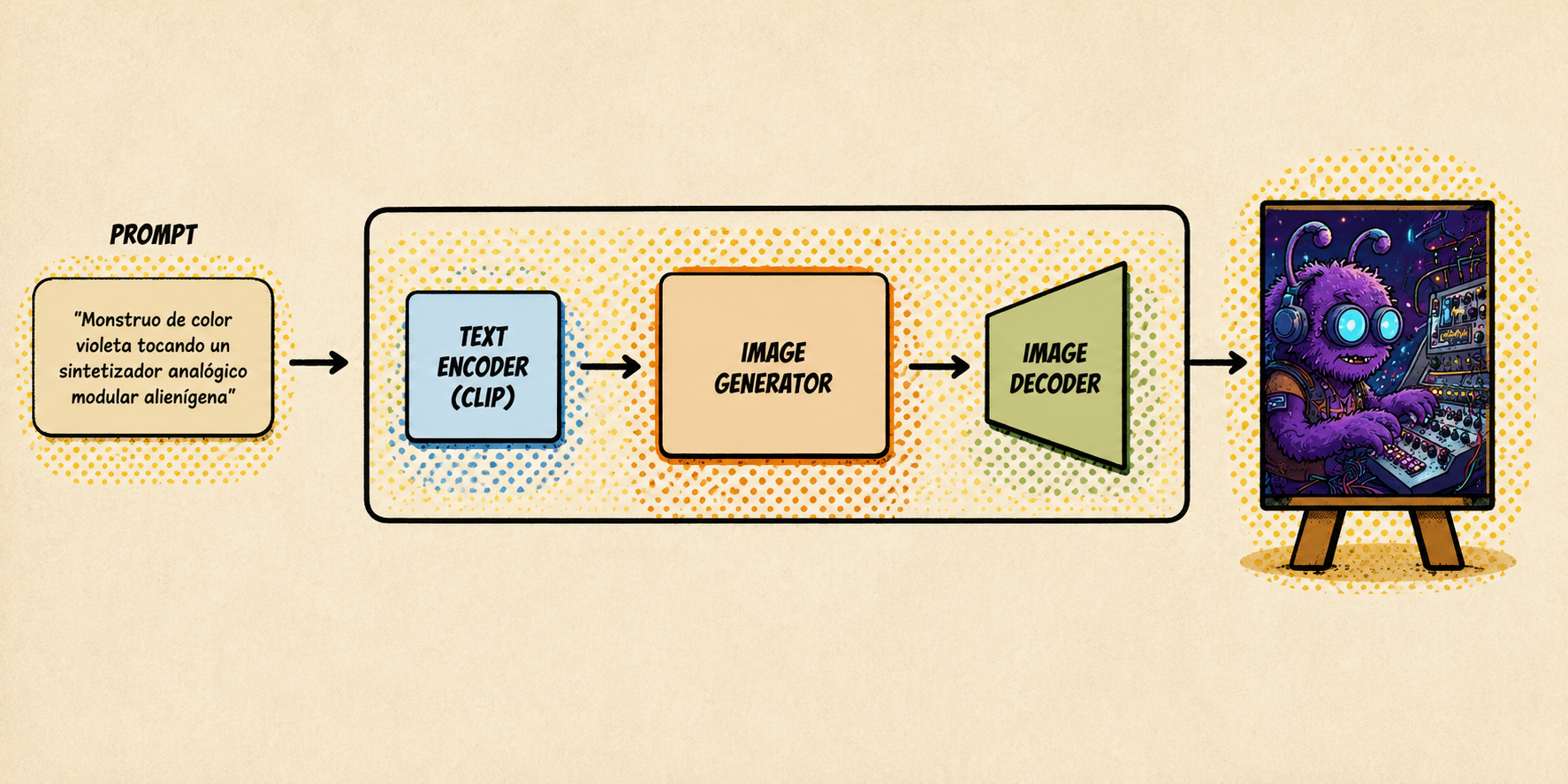
Podemos pensar en Stable Diffusion como tres bloques principales:
- Text encoder: convierte el prompt de texto en una representación numérica.
- Image generator: genera una representación latente de la imagen guiándose por el texto.
- Image decoder: reconstruye la representación latente a la dimensión objetivo de la imagen.
Text encoder: CLIP
En primer lugar el modelo necesita convertir los prompts en vectores que una red neuronal pueda utilizar.
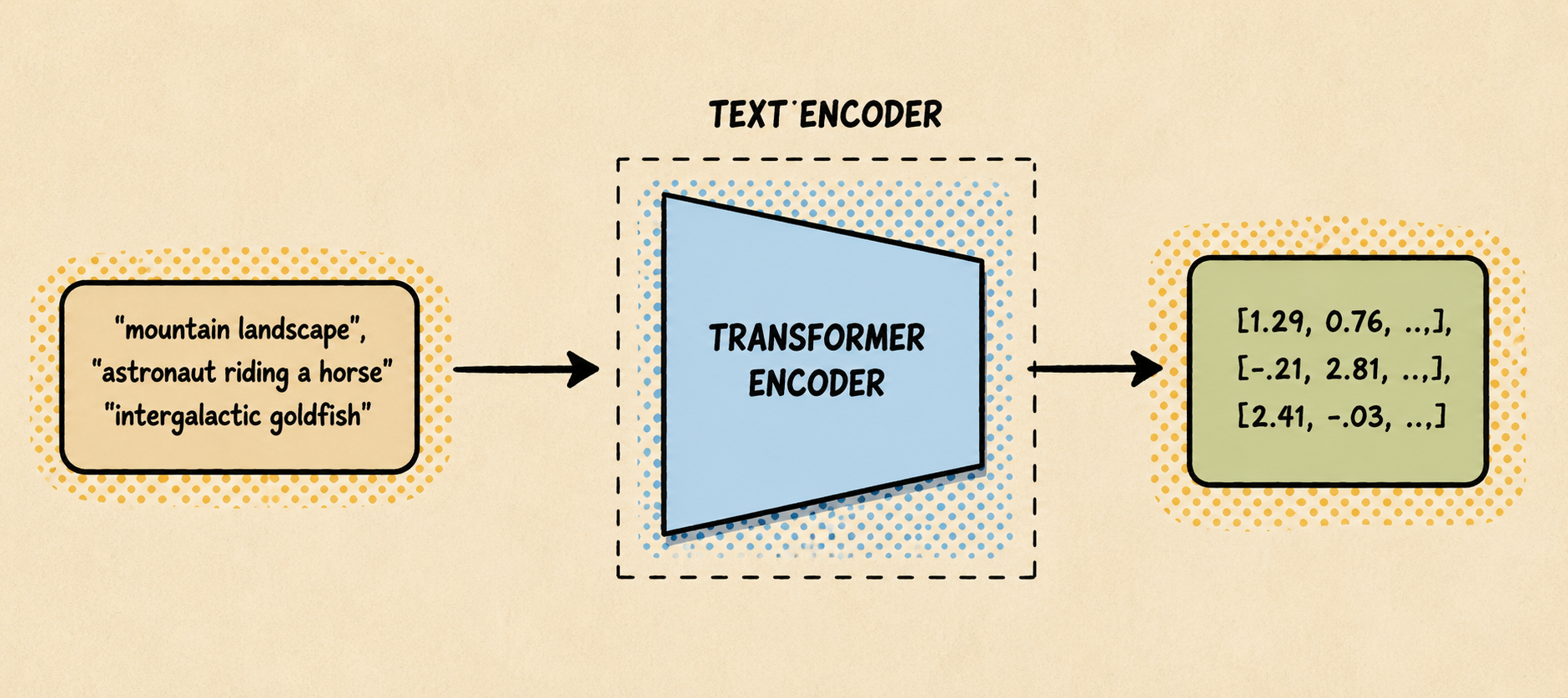
Normalmente este encoder es un encoder de un transformer. Técnicamente, el encoder de texto de un modelo tipo CLIP. CLIP es una técnica para entrenar con pares de imágenes y textos para aprender representaciones donde una imagen y su descripción queden cerca en el espacio vectorial.
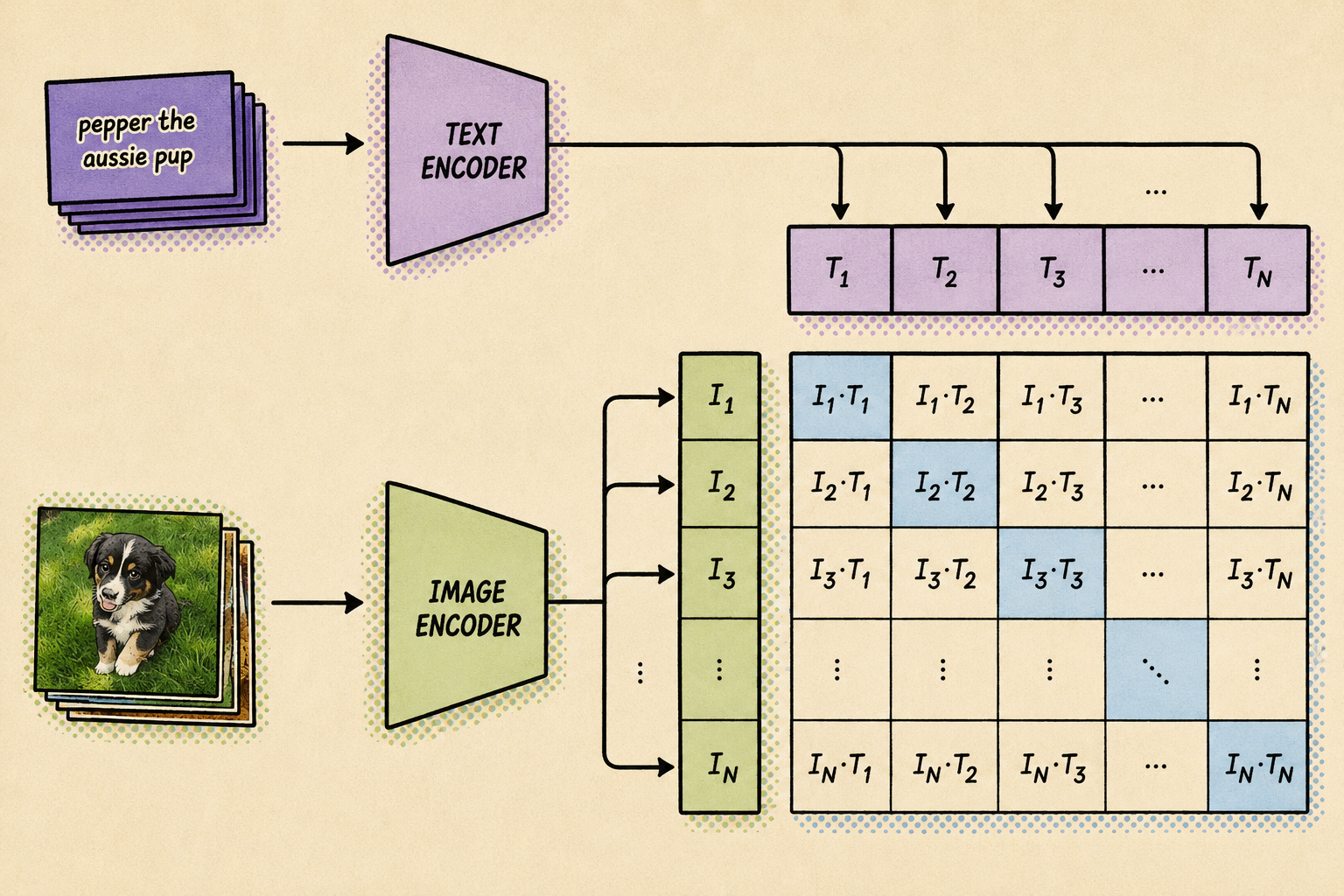
Los embeddings de texto y de imagen se comparan mediante la similitud del coseno. Al inicio del proceso de entrenamiento, la similitud será baja, aunque el texto describa correctamente la imagen simplemente porque los espacios vectoriales de cada encoder son diferentes. Lo que se hace entonces es actualizar los dos pesos de ambos modelos para que la próxima vez los embeddings resultantes sean similares.
Repitiendo esta operación, al final del entrenamiento se consigue que los encoders sean capaces de producir embeddings en las que una imagen de un perro y la frase «una foto de un perro» quedan en zonas similares del espacio latente.
Stable Diffusion utiliza el text encoder de CLIP para convertir el prompt en una secuencia de embeddings:
Ese vector es una representación semántica del texto: contiene información sobre objetos, estilos, relaciones y detalles que el modelo usará para guiar la generación.
Image generator
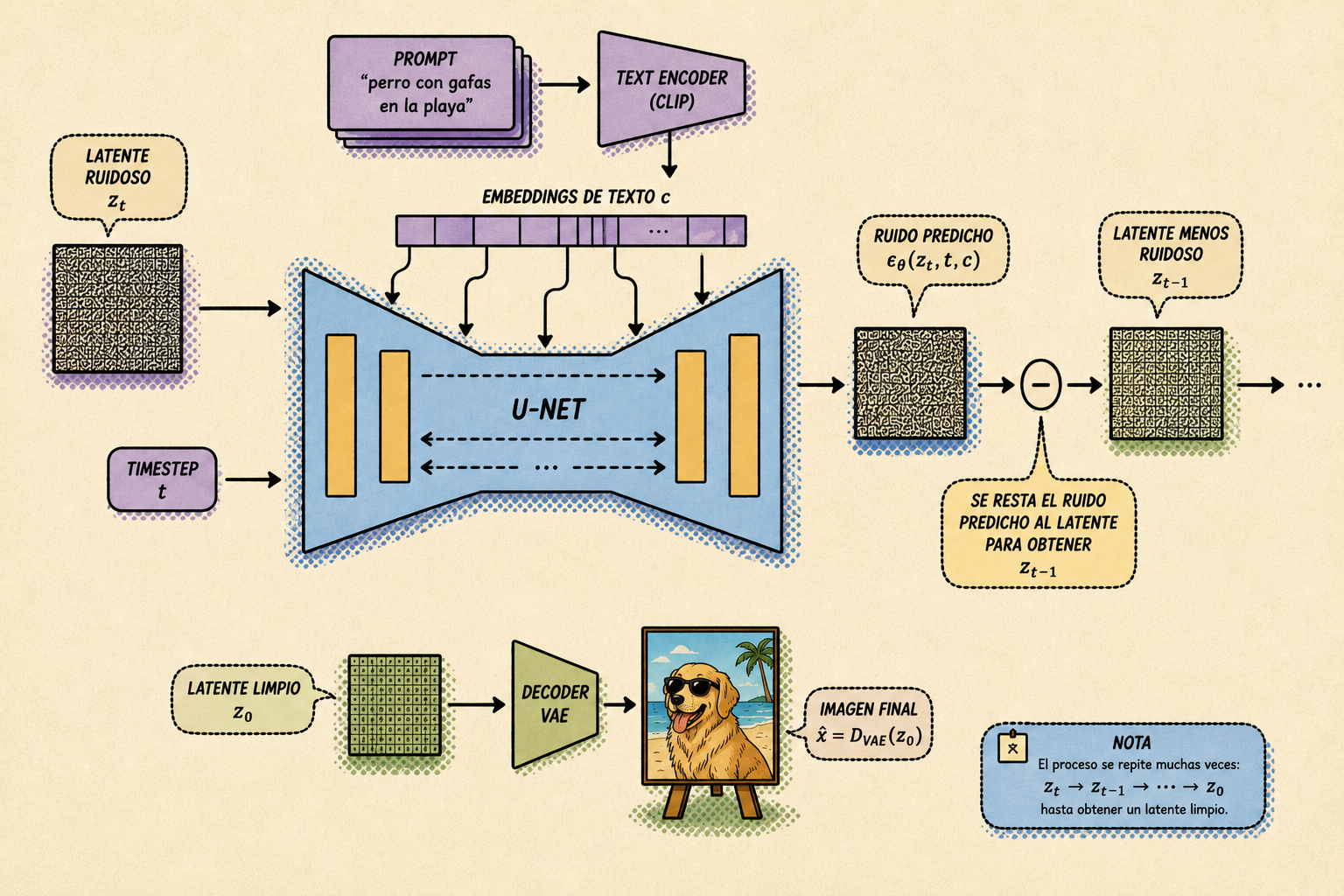
El nombre "image generator" puede llevar a confusión, porque en Stable Diffusion este componente la parte no produce píxeles directamente si no que genera un matriz en el espacio latente.
El bloque central es una U-Net. Esta red recibe:
- un latente ruidoso ;
- el timestep ;
- el condicionamiento textual producido por CLIP.
Y predice el ruido que hay que retirar:
Después, un scheduler usa esa predicción para calcular un latente un poco menos ruidoso:
Este proceso se repite muchas veces hasta obtener un latente limpio .
La U-Net usa mecanismos de cross-attention para mezclar la información visual del latente con la información textual del prompt. Gracias a esto, el modelo puede decidir qué partes de la imagen deberían prestar atención a qué partes del texto.
Cuando termina el denoising, todavía no tenemos una imagen visible, sino un latente limpio. Para convertirlo a píxeles, Stable Diffusion usa el decoder de un VAE:
Entrenamiento
Durante el entrenamiento, el modelo aprende principalmente a quitar ruido en el espacio latente.
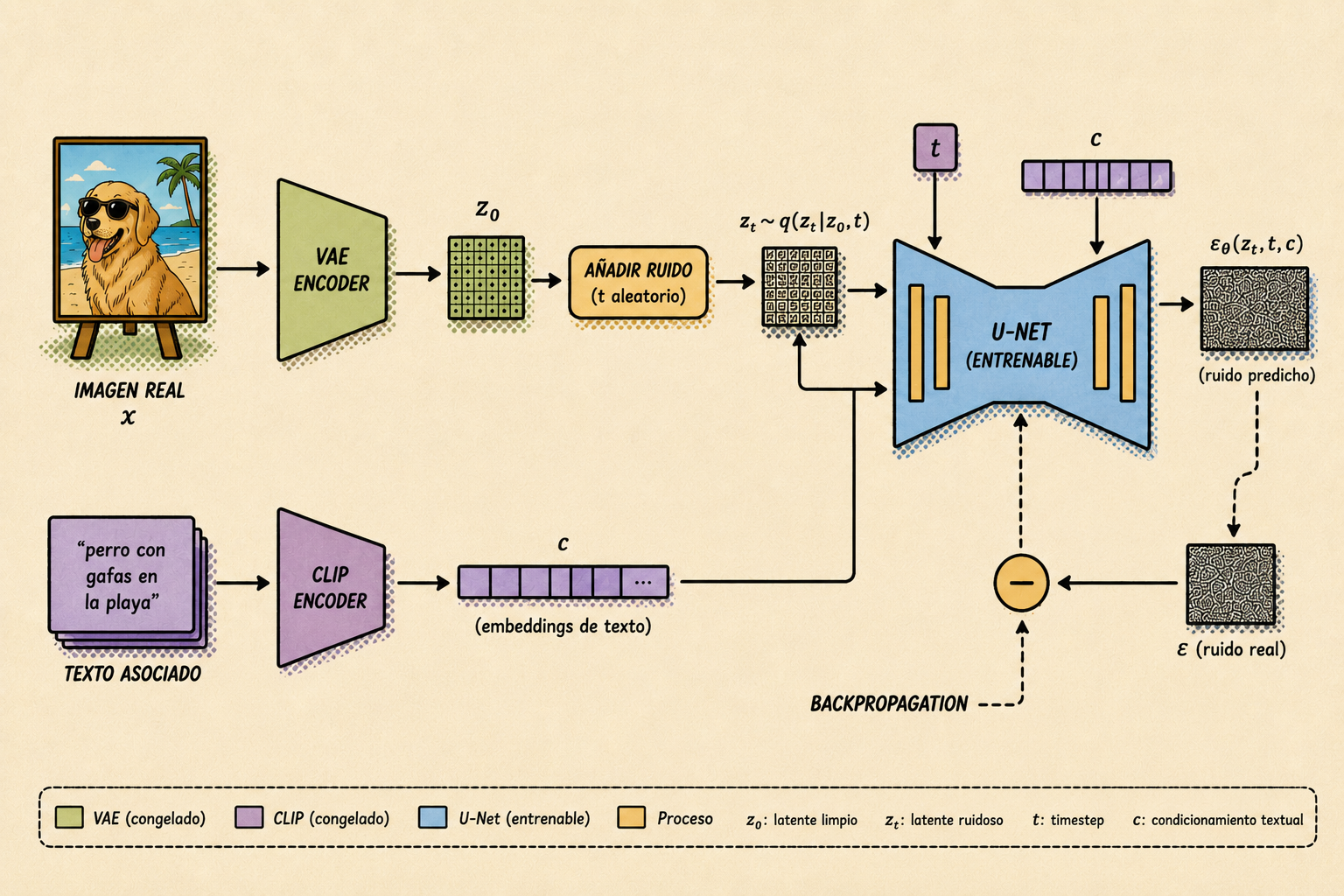
El proceso típico es:
- Se toma una imagen real y su texto asociado.
- Se codifica la imagen con el encoder del VAE para obtener un latente .
- Se codifica el texto con CLIP para obtener el condicionamiento .
- Se elege un timestep aleatorio .
- Se añade ruido al latente para obtener .
- La U-Net recibe y predice el ruido añadido.
- Se compara el ruido real con el ruido predicho.
La pérdida se parece a la de los modelos de difusión que vimos antes, pero ahora se aplica en el espacio latente:
En muchas implementaciones, el VAE y el text encoder ya están preentrenados y se mantienen congelados durante el entrenamiento principal. La parte que aprende a generar es la U-Net de denoising.
Inferencia
La inferencia es el proceso de usar el modelo ya entrenado para generar una imagen nueva.
El flujo típico es:
- Escribimos un prompt.
- CLIP convierte el prompt en embeddings de texto .
- Muestreamos un latente inicial aleatorio .
- La U-Net predice ruido en el latente actual.
- El scheduler actualiza el latente para hacerlo un poco menos ruidoso.
- Repetimos los pasos 4 y 5 durante varios timesteps.
- El VAE decoder convierte el latente final en una imagen.
Diferencias con Flow Matching
Los modelos de difusión y Flow Matching están muy relacionados. Ambos parten de una distribución simple, normalmente ruido gaussiano, y aprenden a transformarla en una distribución objetivo.
La diferencia principal está en qué aprende el modelo.
En difusión, el modelo aprende a quitar ruido:
Es decir, recibe una muestra ruidosa y predice qué parte de esa muestra corresponde al ruido añadido.
En Flow Matching, el modelo aprende una velocidad:
Es decir, recibe un punto intermedio y predice hacia dónde debería moverse para avanzar desde la distribución inicial hacia la distribución de datos.
Durante el entrenamiento
En difusión, construimos ejemplos ruidosos añadiendo ruido conocido a datos reales:
Como conocemos , entrenamos a la red para predecir ese ruido.
En Flow Matching, construimos puntos intermedios entre una muestra inicial y un dato :
Y entrenamos a la red para predecir la velocidad que seguiría ese camino:
En ambos casos fabricamos un problema supervisado: generamos artificialmente un estado intermedio y sabemos cuál debería ser la respuesta correcta.
Durante la generación
En difusión, empezamos desde ruido y vamos aplicando pasos de denoising:
En Flow Matching, empezamos desde ruido y seguimos un campo de velocidades:
La generación también avanza de ruido a datos, pero la interpretación cambia. Difusión lo ve como una cadena de eliminación de ruido. Flow Matching lo ve como una trayectoria continua guiada por velocidades.